06-cs01-eda
20234-10-02
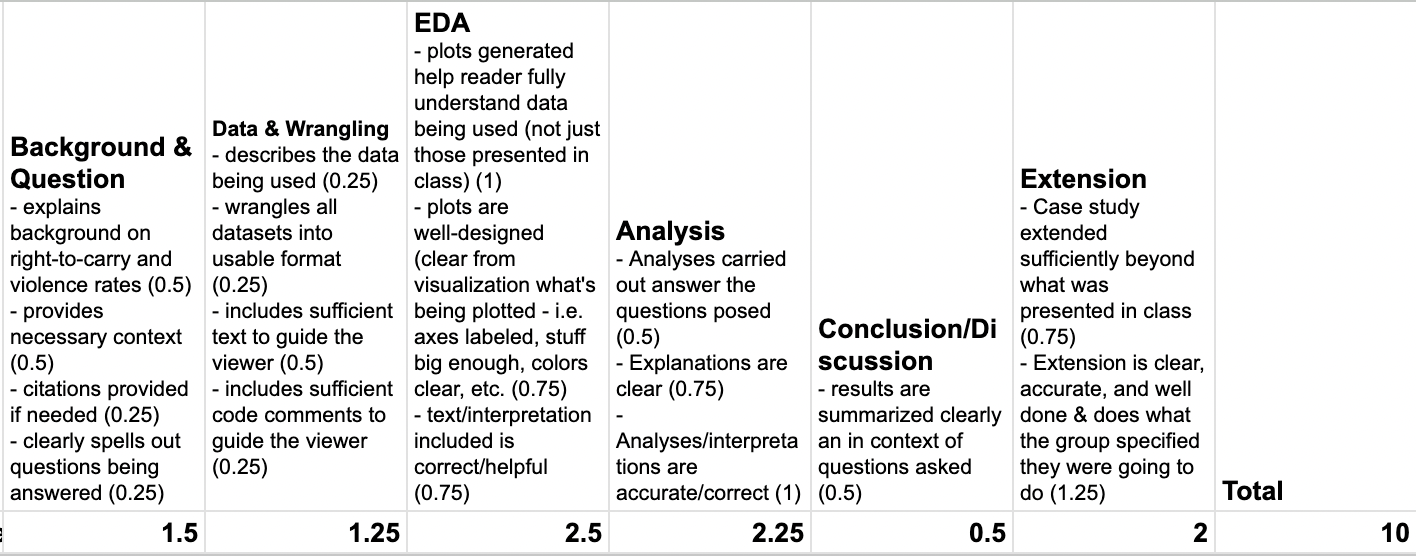
An (Example) Rubric
This is NOT the rubric for your case study, but it will be similar:
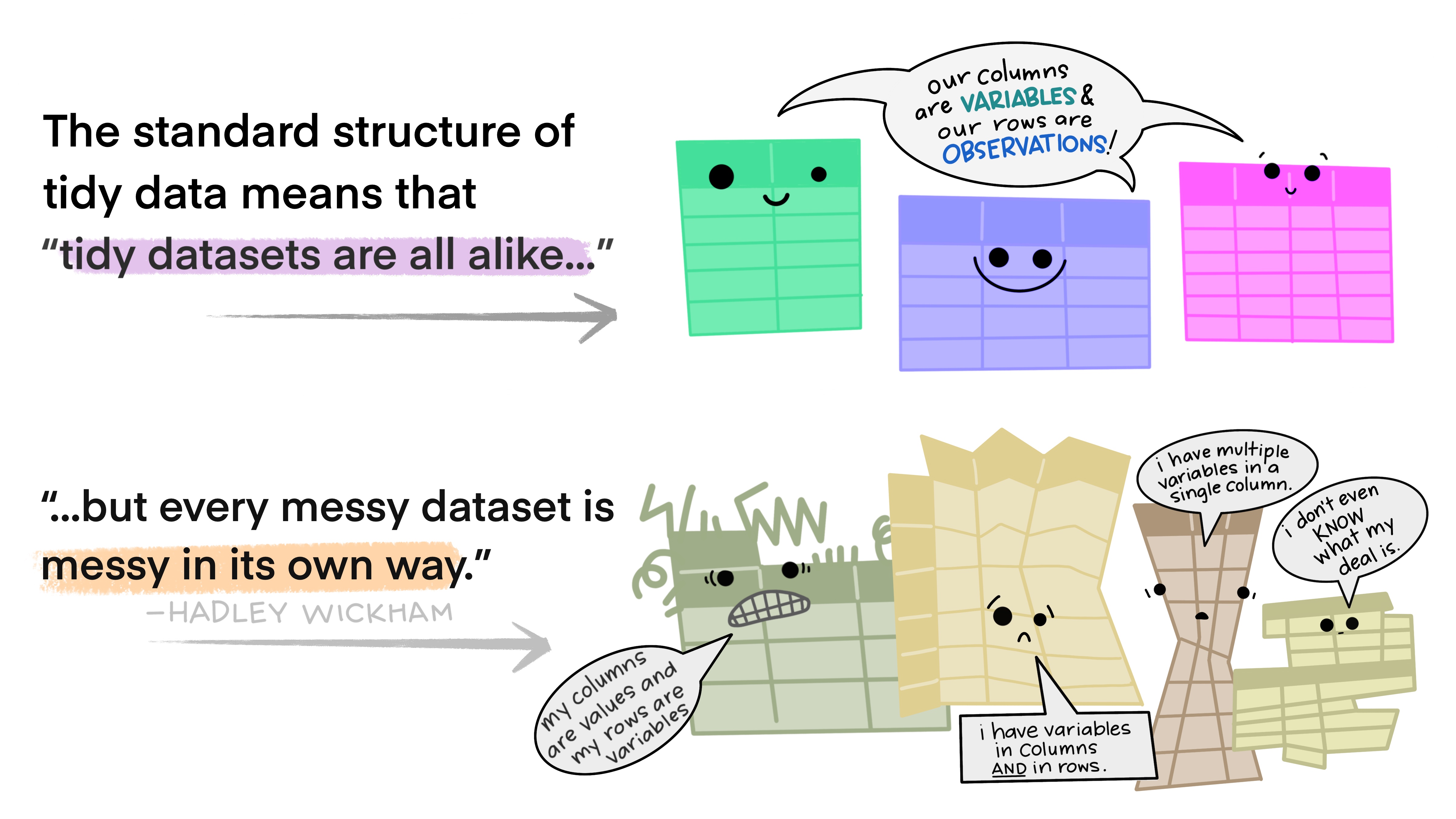
Reminder: Tidy Data

Joins
Combining data across different datasets, using common information (often: IDs)
Mutating Joins
add new variables to a data frame from matching observations in another
left_join: keeps all rows in first df; adds all matching information from second df; adds NAs for any observations missing informationright_join: keeps all observations in second dffull_join: keeps all observations in either df
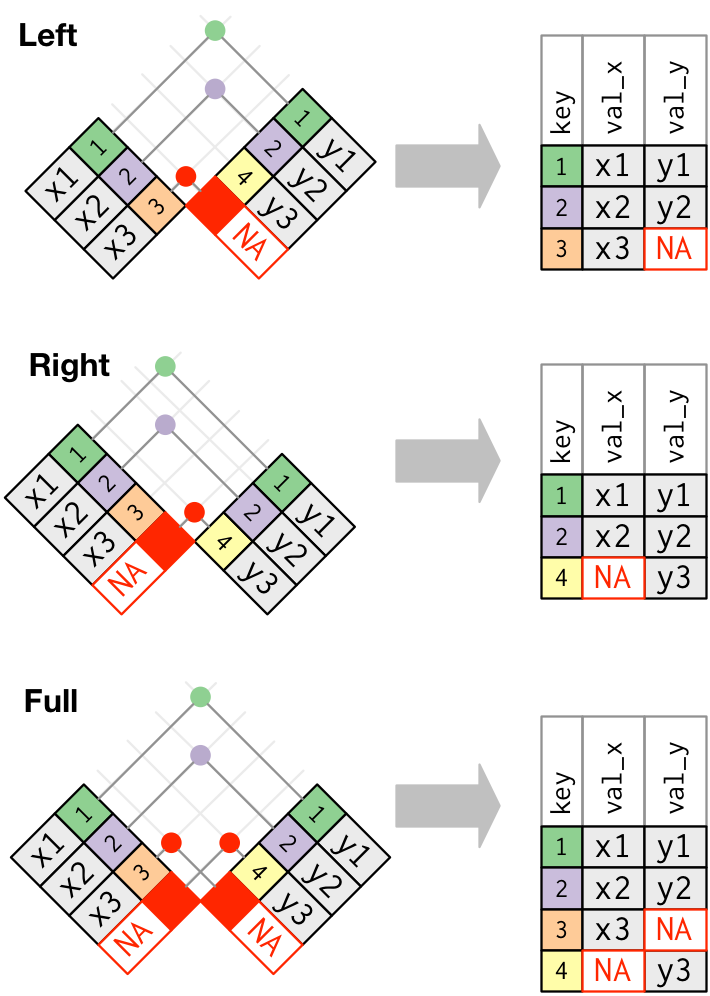
inner_join: takes only rows in both dfs
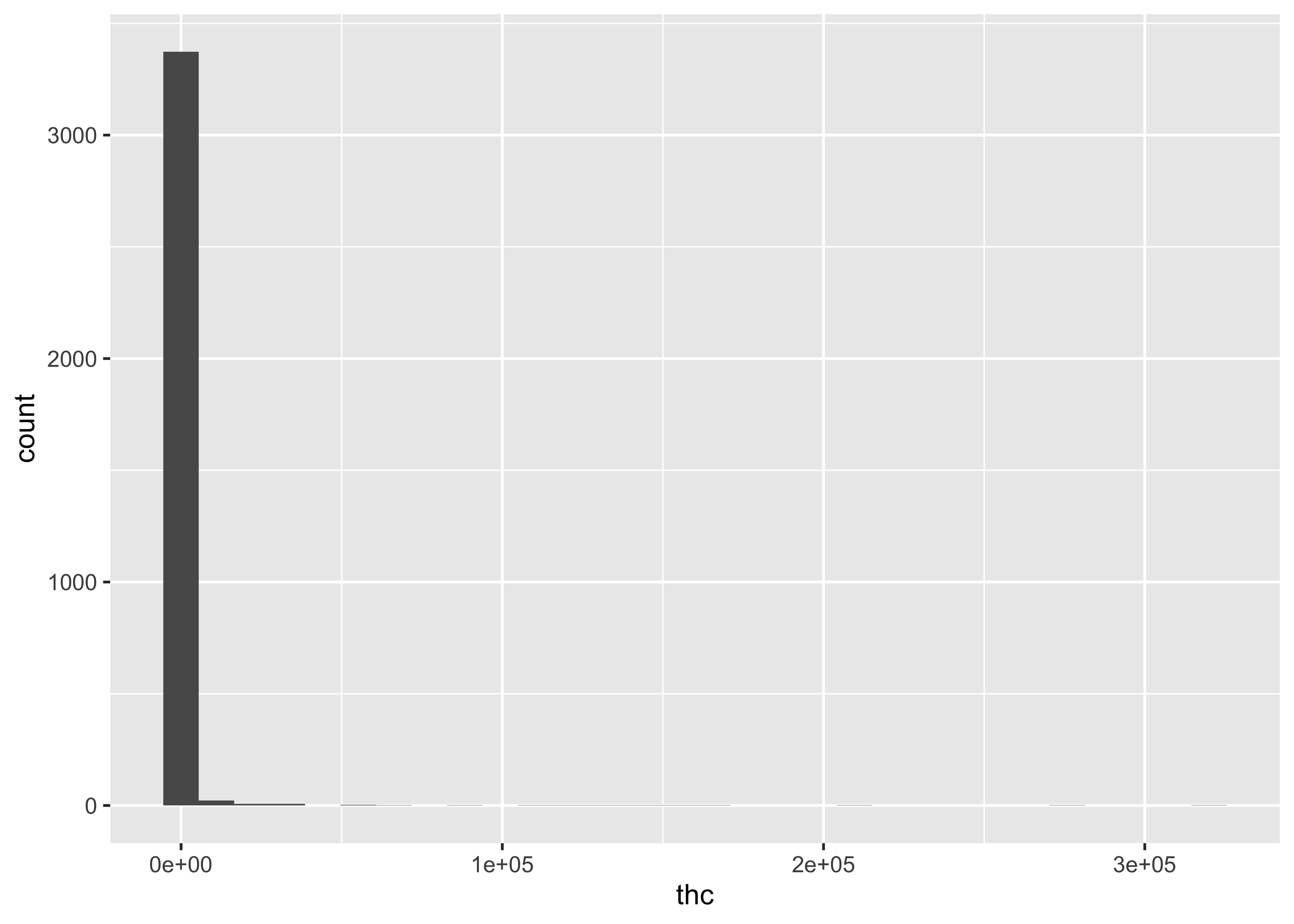
Single Variable (basic) plots
For a single compound…
But, we have three different matrices…
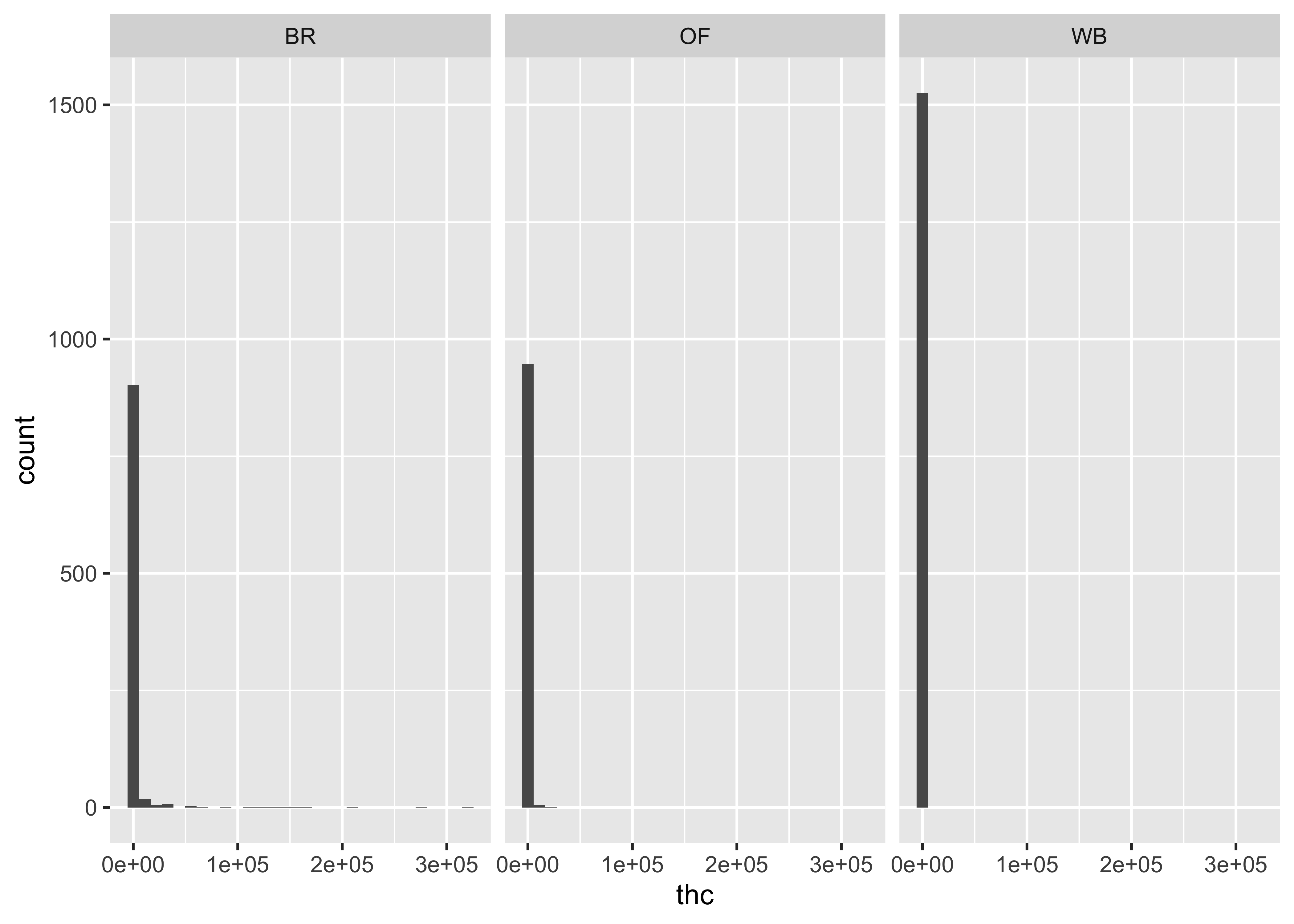
But what if we consider our experiment/the structure of our data? We have three different matrices…and a whole bunch of compounds. With wide data, it’s not easy to plot these distributions, so you may want to pivot those data….
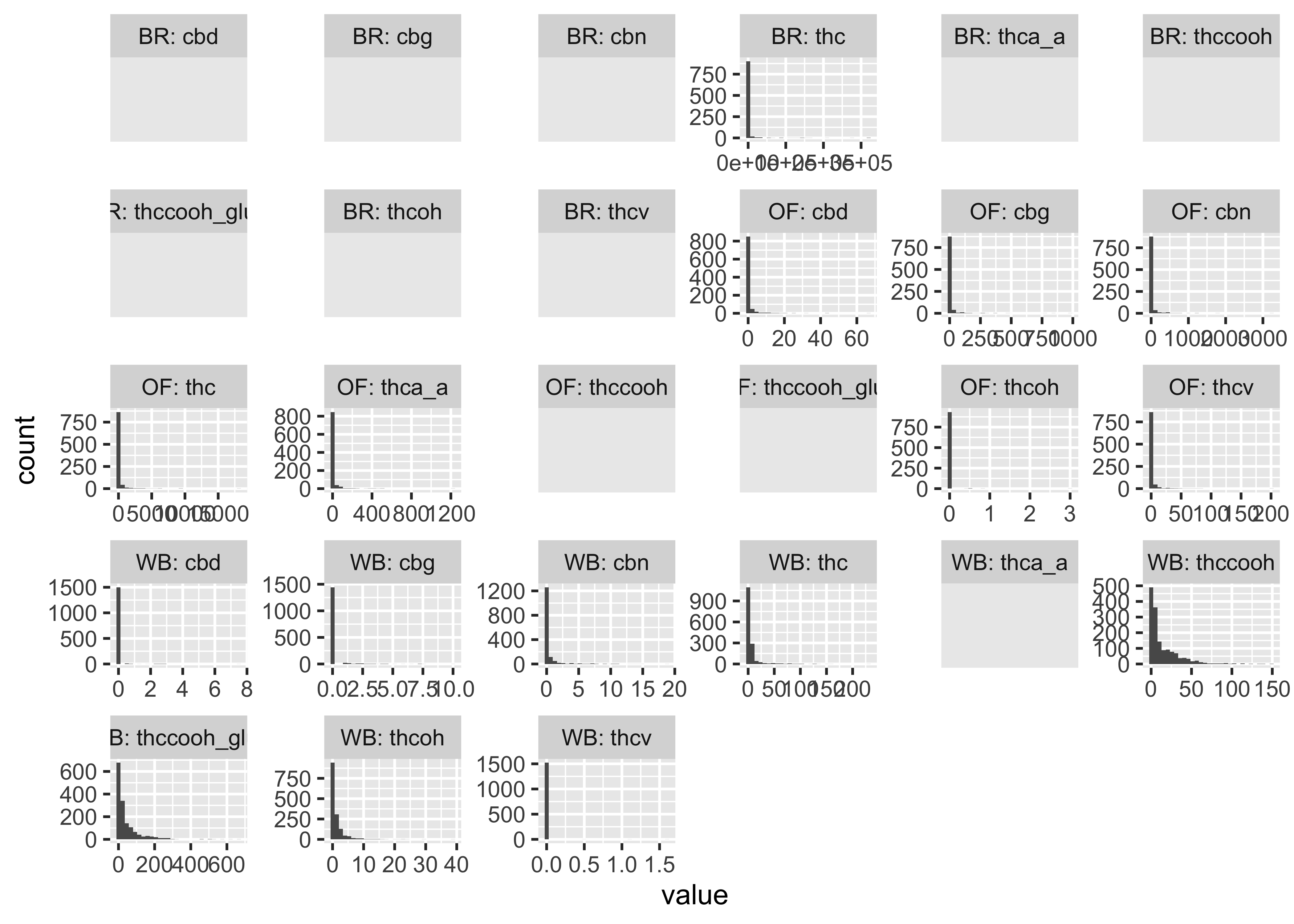
Distributions across all compounds:
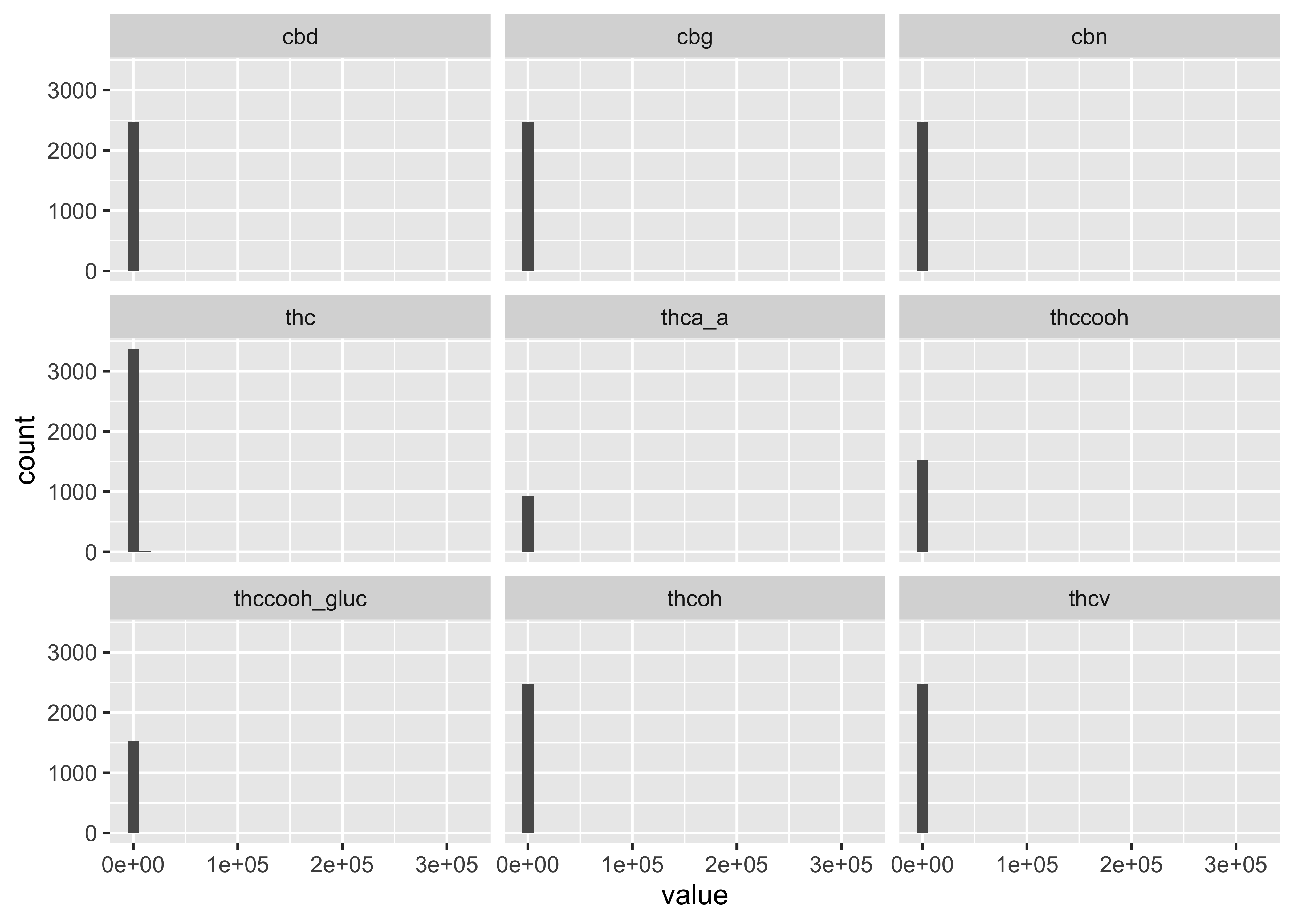
…but this still doesn’t get at the differences between matrices and compound.
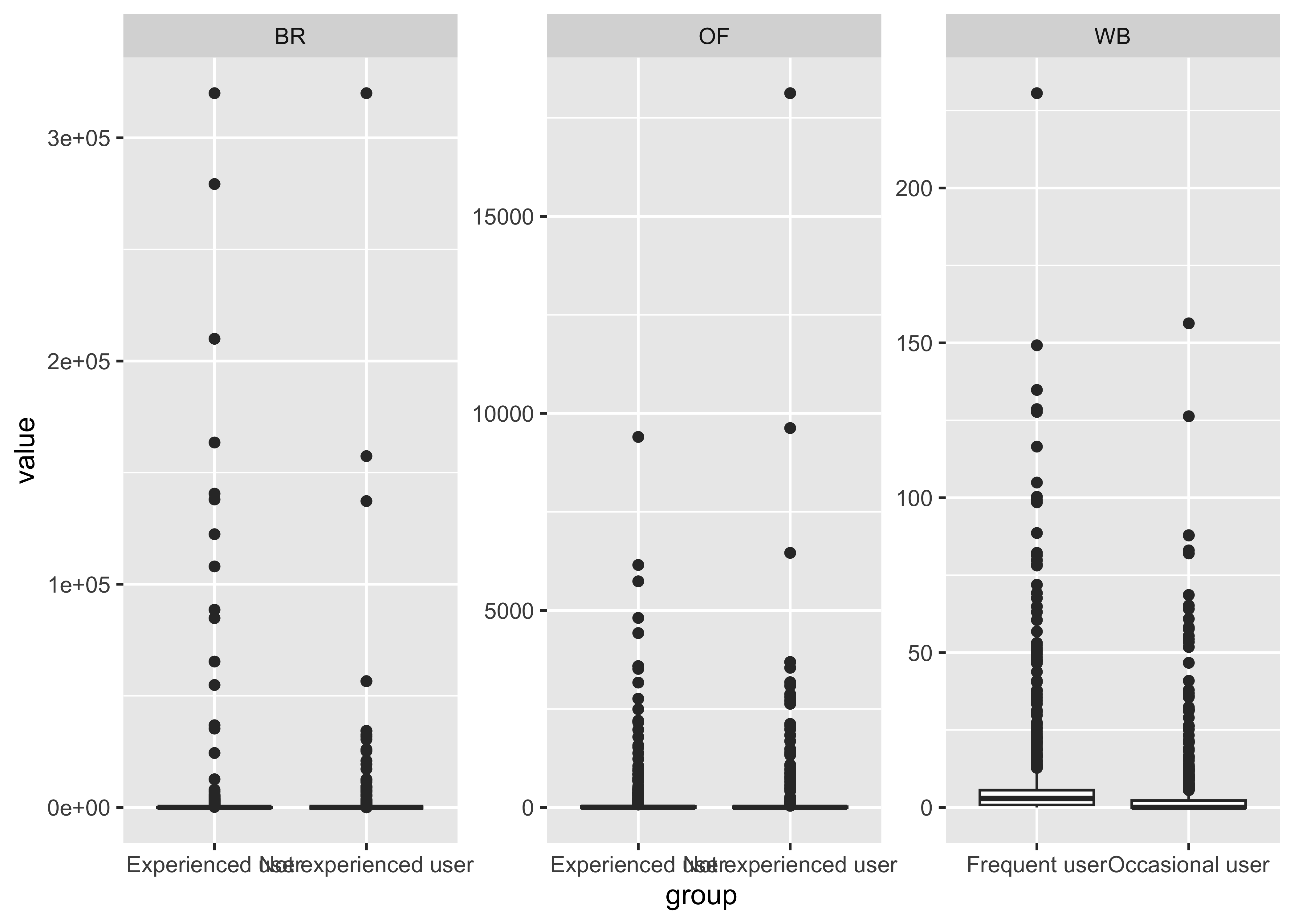
THC & Frequency
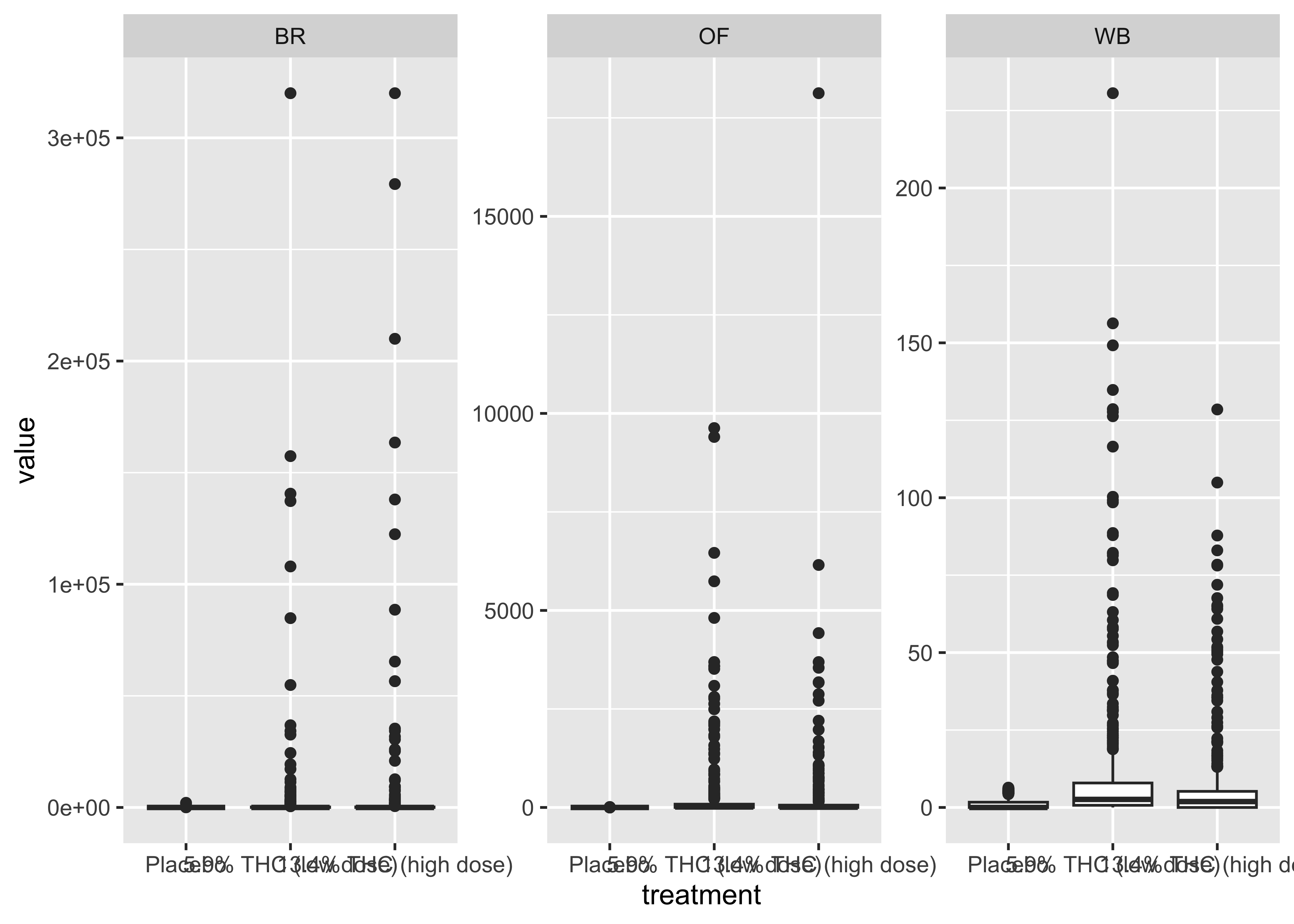
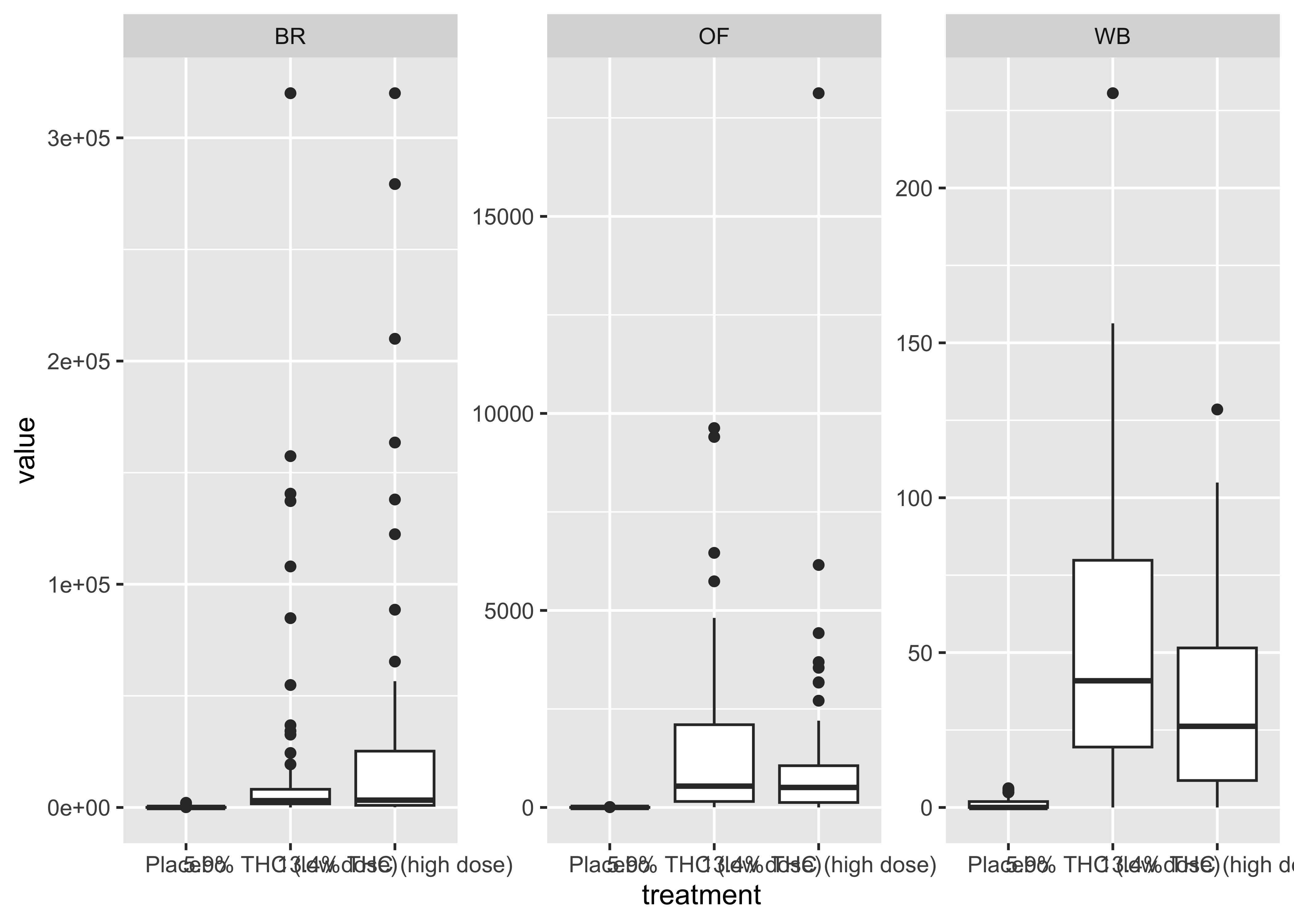
THC & Treatment Group
Focus on a specific timepoint…
Compounds across time
Our first user-defined function:
plot_scatter_time <- function(matrix) {
cs01_long |>
filter(!is.na(time_from_start), fluid_type==matrix) |>
ggplot(aes(x=time_from_start, y=value, color=group)) +
geom_point() +
facet_wrap(~name, scales="free") +
scale_color_manual(values=c("#19831C", "#A27FC9")) +
theme_classic() +
labs(title=matrix,
x="Time From Start (min)") +
theme(legend.position="bottom",
legend.title=element_blank(),
strip.background=element_blank(),
plot.title.position="plot")
}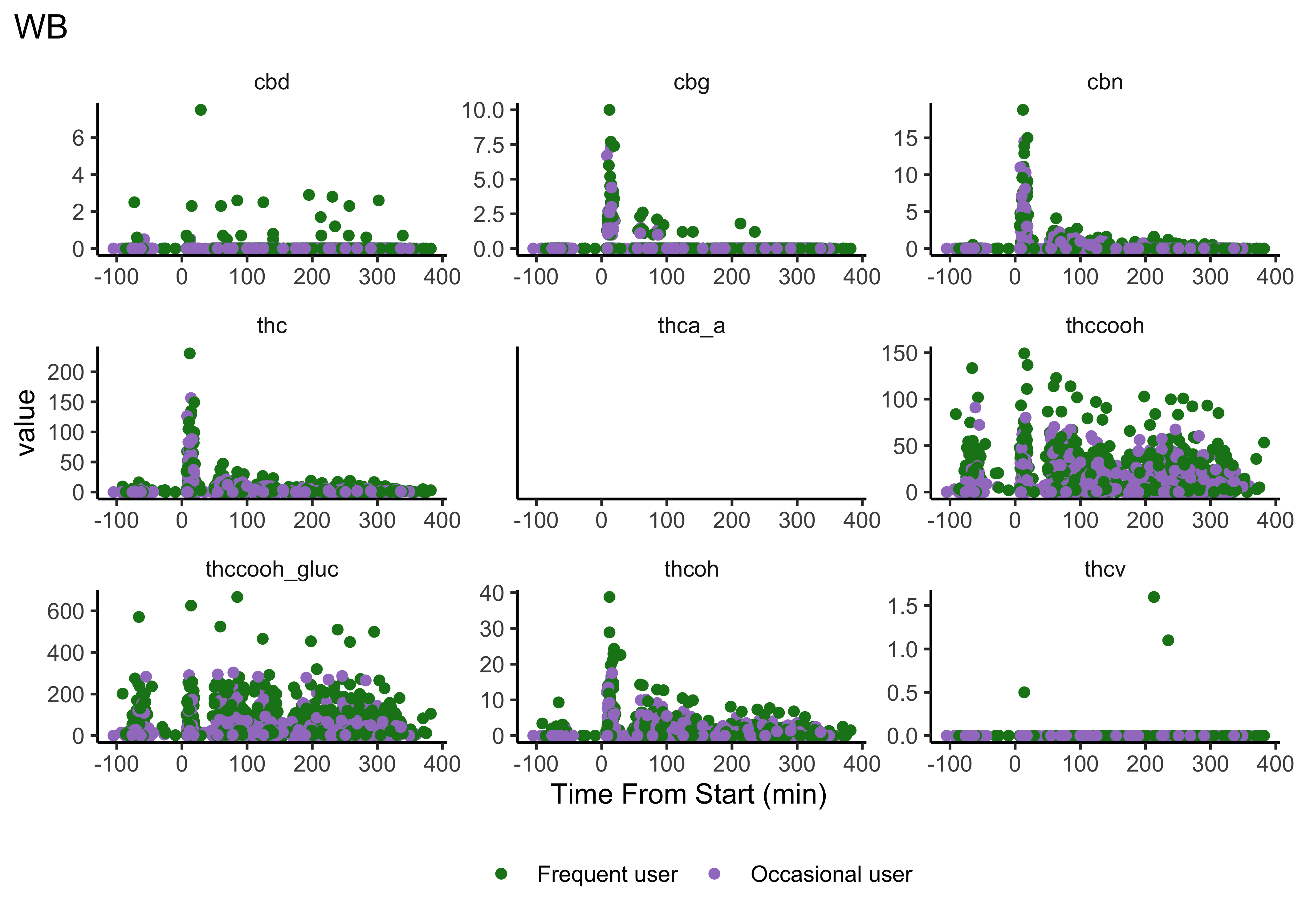
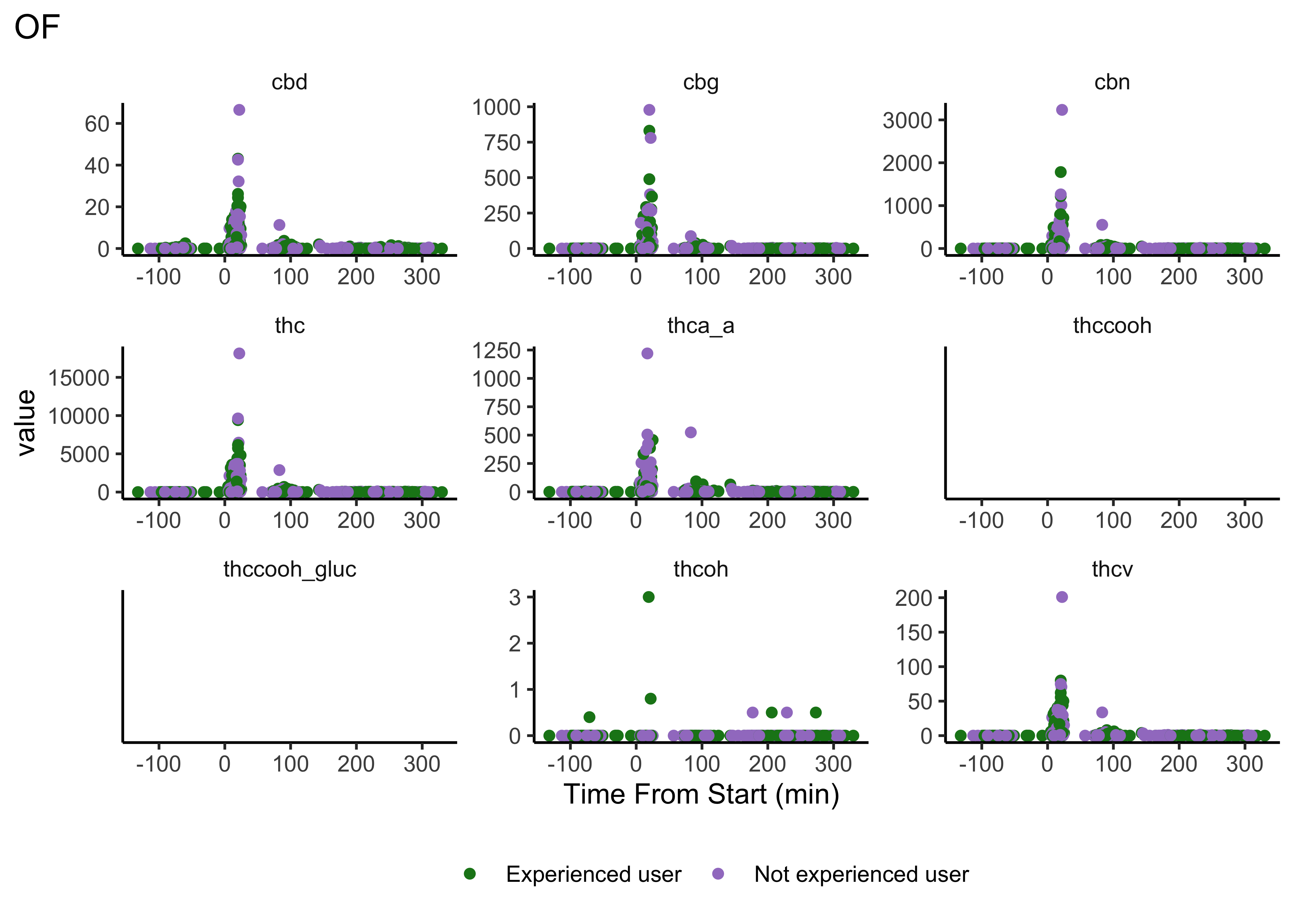
- We do NOT have clear delineations in time
- This means there could be multiple measurements from a single individual within a specified timepoint (i.e. “0-30 min”)
- We wouldn’t want to include duplicate measures from the same individual within timepoint
- We wouldn’t have known this without looking at our data…why EDA is necessary
Group Differences: Frequency of Use
boxplot_frequency_of_use <- function(matrix){
cs01_nodups_long |>
filter(fluid_type == matrix,
timepoint == "0-30 min" | timepoint == "0-40 min") |>
ggplot(aes(x=group, y=value, fill=group)) +
geom_jitter(position=position_jitter(width=.3,
height=0),
size=0.8,
color="gray50") +
geom_boxplot(outlier.shape=NA, alpha=0.6) +
facet_wrap(~name, scales="free") +
scale_x_discrete(labels=function(x) str_wrap(x, width=10)) +
scale_y_continuous(limits=c(0, NA),
expand=expansion(mult=c(0, 0.1))) +
scale_fill_manual(values=c("#19831C", "#A27FC9")) +
theme_classic() +
labs(title=paste0(matrix)) +
theme(text=element_text(size=12),
legend.position="bottom",
legend.title=element_blank(),
panel.grid=element_blank(),
plot.title.position="plot",
strip.background=element_blank())
}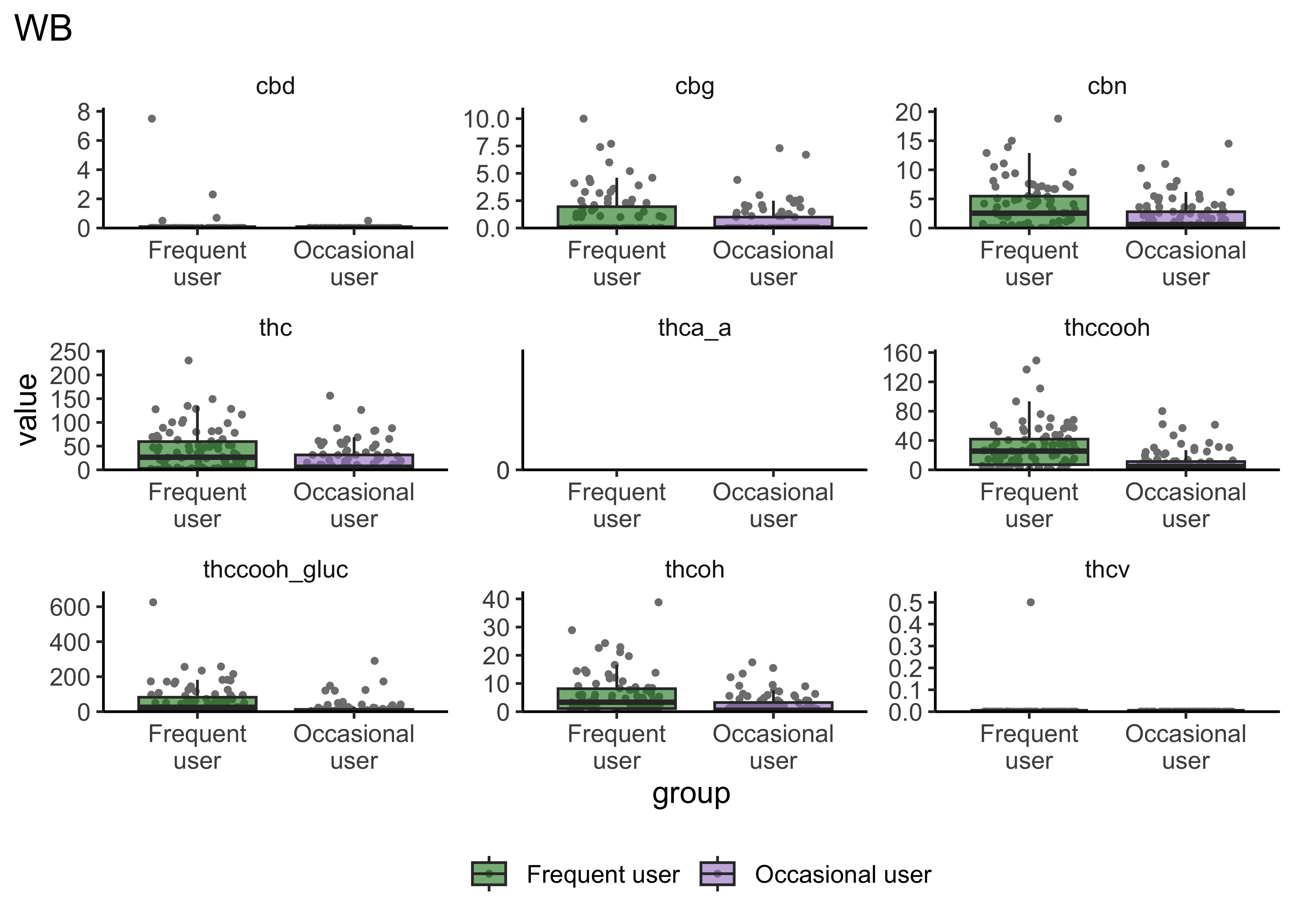
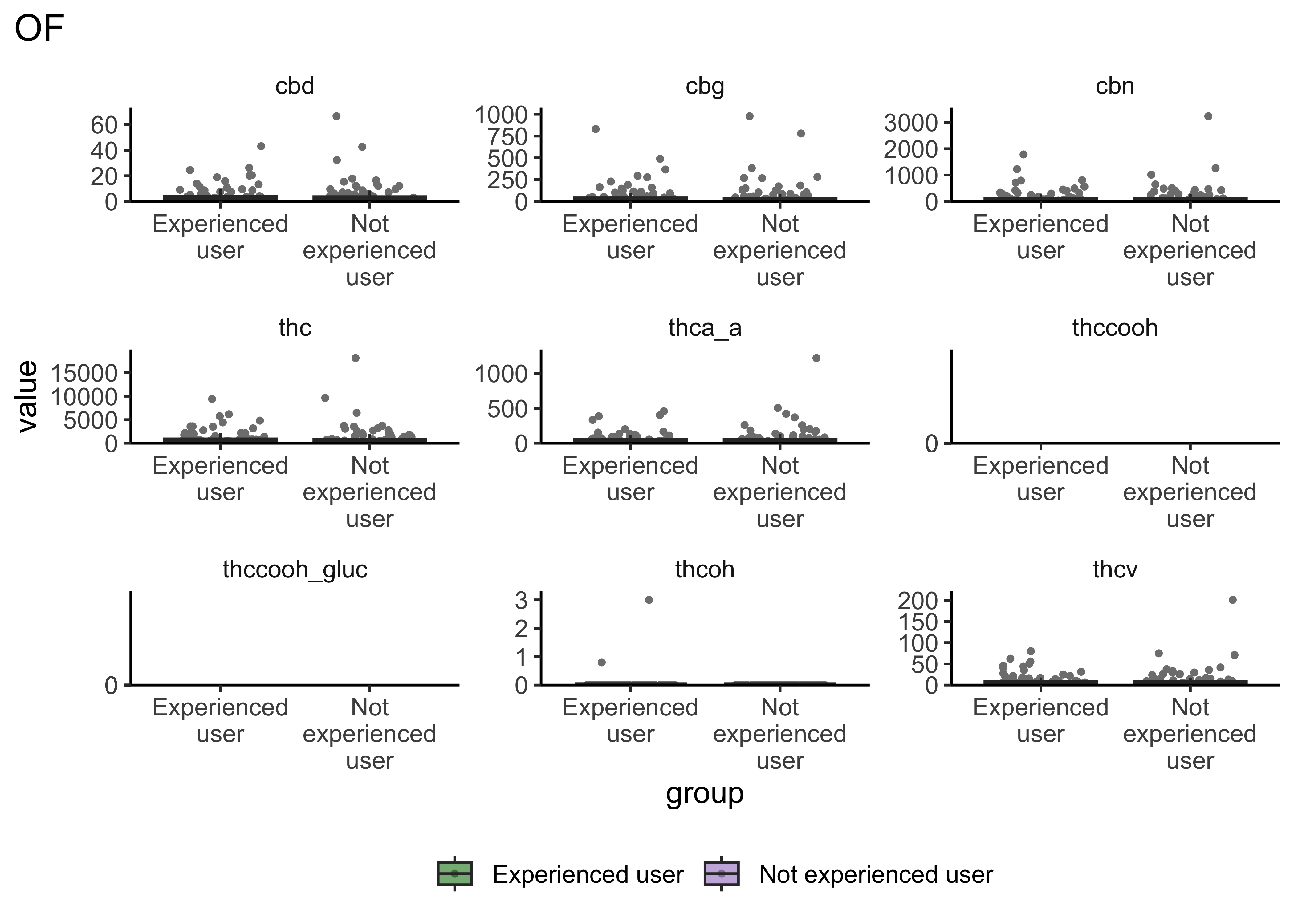
- Certain compounds show different values between frequent and infrequent users. Worth considering what that means for our ultimate goal
- Breath at this first timepoint likely not very helpful…what about other timepoints?
Group Differences: Treatment
boxplot_treatment <- function(matrix){
cs01_nodups_long |>
filter(fluid_type == matrix,
timepoint == "0-30 min" | timepoint == "0-40 min") |>
ggplot(aes(x=treatment, y=value, fill=group)) +
geom_jitter(position=position_jitter(width=.3,
height=0),
size=0.8,
color="gray50") +
geom_boxplot(outlier.size=0.1, alpha=0.8) +
facet_wrap(~name, scales="free") +
scale_x_discrete(labels = function(x) str_wrap(x, width = 10)) +
scale_y_continuous(limits=c(0, NA),
expand=expansion(mult=c(0, 0.1))) +
scale_fill_manual(values=c("#19831C", "#A27FC9")) +
theme_classic() +
labs(title=paste0(matrix), y="Measurement (ng/mL)") +
theme(text=element_text(size=12),
legend.position="bottom",
legend.title=element_blank(),
panel.grid=element_blank(),
plot.title.position="plot",
strip.background=element_blank())
}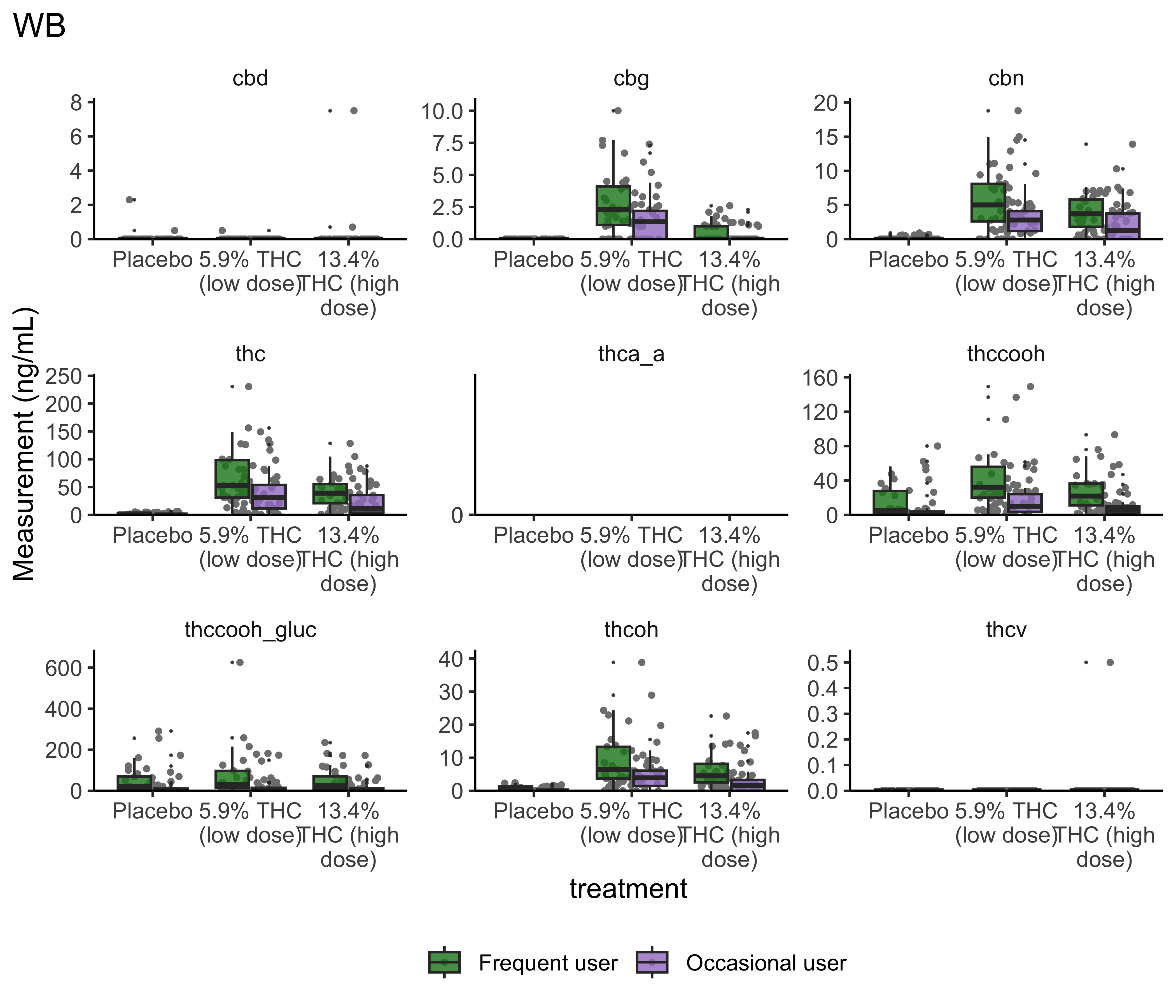
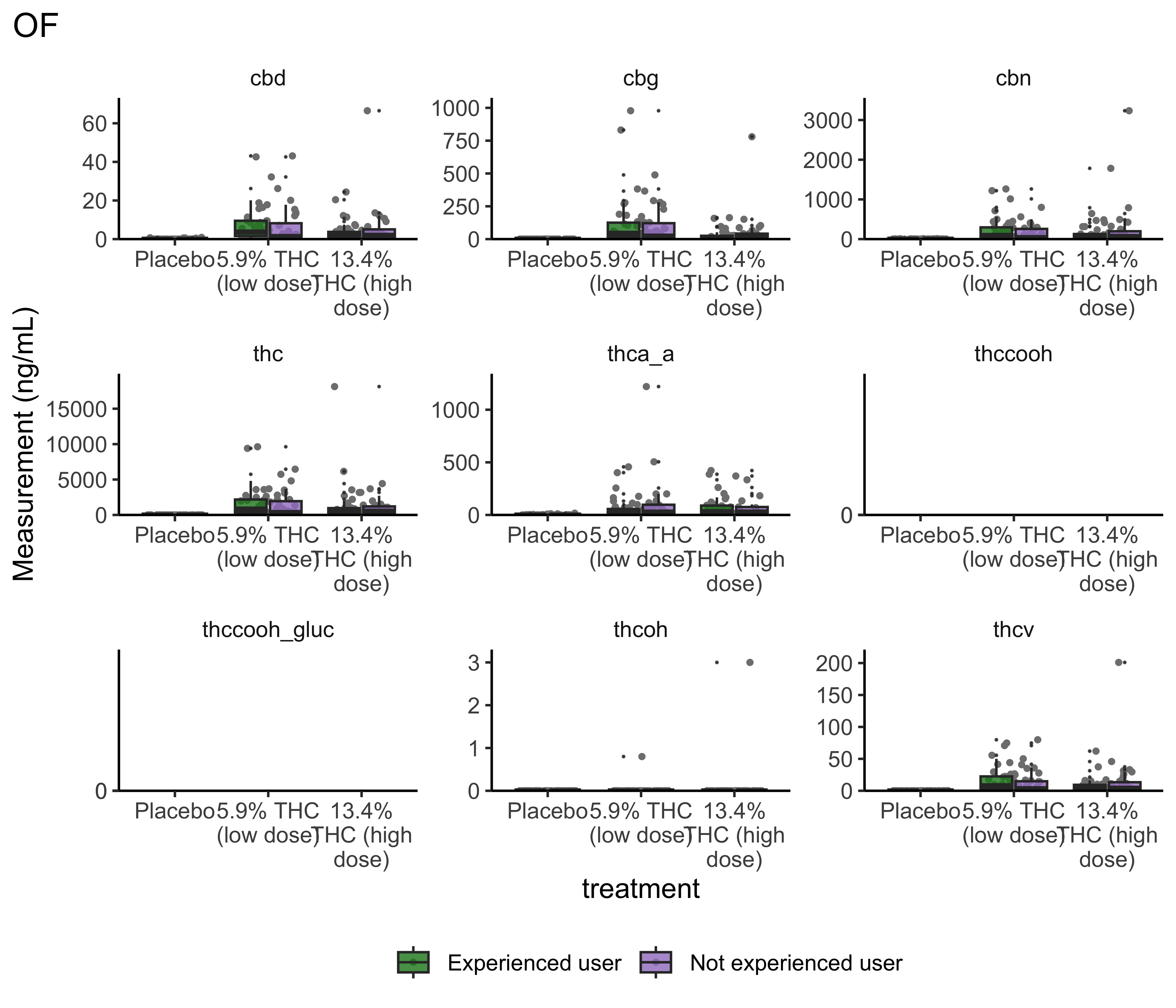
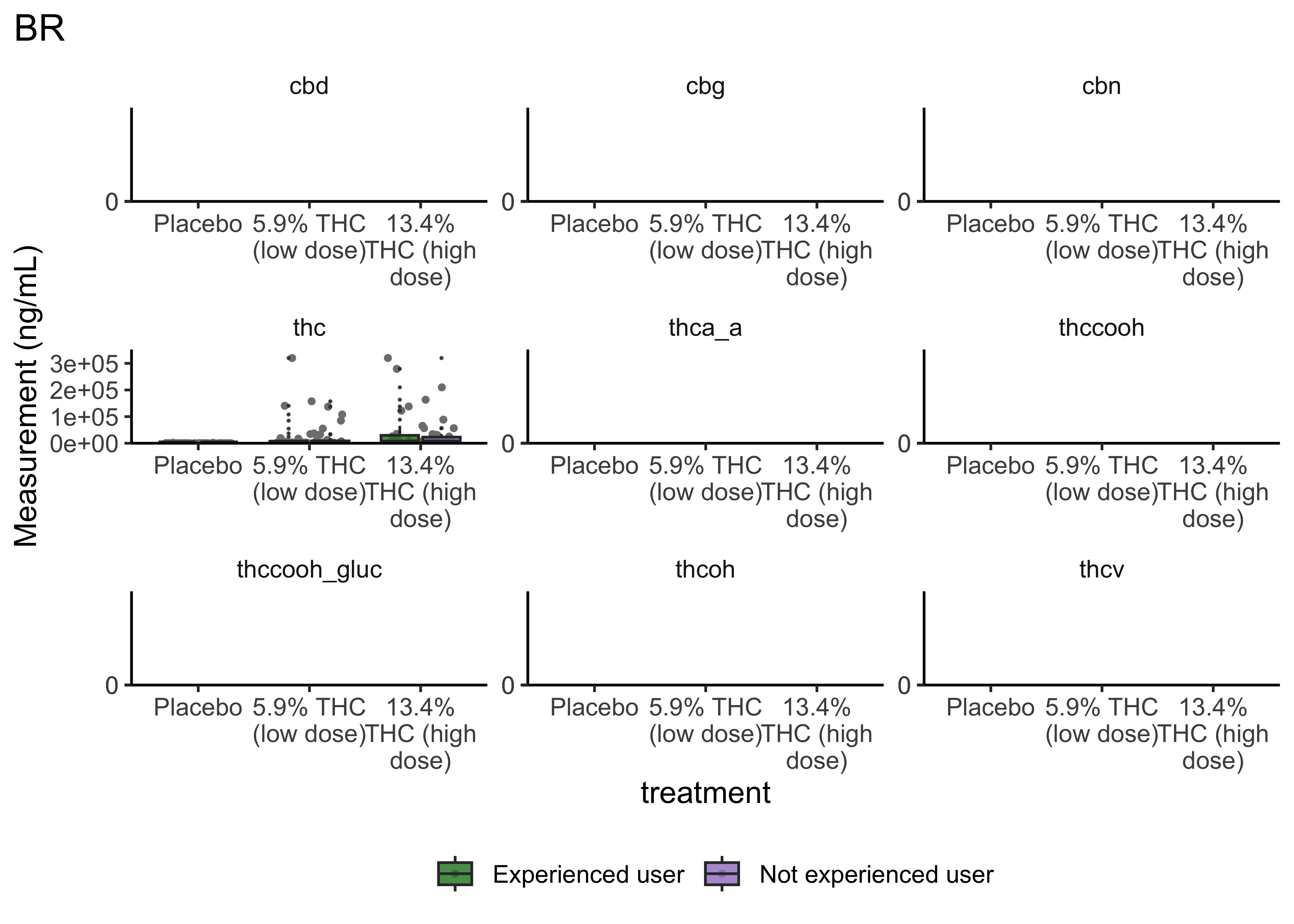
- Argument for combining treatment groups?
- We now have very similar
ggplot2code across a few plots. This can be improved usingtheme_set(). You set theme parameters at top of Rmd…and then those will apply across all plots. - These last two sets of plots have only focused on that first timepoint. You’ll probably want to look beyond that.
Plot Results
Note: requires library(patchwork)
plot_cutoffs <- function(dataset, timepoint_use_variable, tissue, cpd){
# control colors and lines used in plots
col_val = c("#D9D9D9", "#BDBDBD", "#969696", "#636363", "#252525")
lines = rep("solid", 5)
# prep data
df_ss <- dataset |>
filter(compound == cpd) |>
mutate(time_window = fct_relevel(as.factor(time_window), levels(timepoint_use_variable)),
detection_limit = as.factor(detection_limit),
Sensitivity = round(Sensitivity*100, 0),
Specificity = round(Specificity*100, 0))
# plot sensitivity
p1 <- df_ss |>
ggplot(aes(x = time_window, y = Sensitivity,
color = detection_limit)) +
geom_line(linewidth = 1.2, aes(group = detection_limit,
linetype = detection_limit)) +
geom_point(show.legend=FALSE) +
ylim(0,100) +
scale_x_discrete(labels = function(x) str_wrap(x, width = 5)) +
scale_linetype_manual(values=lines) +
scale_color_manual(values = col_val, name = "Cutoff \n (ng/mL)",
guide = guide_legend(override.aes = list(linetype = c(1),
shape = rep(NA, length(lines))) )) +
theme_classic() +
theme(plot.title.position = "plot",
axis.title = element_text(size=14),
axis.text = element_text(size=10),
legend.position = "none",
panel.grid = element_blank(),
strip.background = element_blank()
) +
guides(linetype = "none") +
labs(x = "Time Window (min)",
y = "Sensitivity",
title = paste0(tissue,": ", toupper(cpd)) )
# plot specificity
p2 <- df_ss |>
ggplot(aes(x = time_window, y = Specificity,
group = detection_limit,
color = detection_limit,
linetype = detection_limit)) +
geom_line(linewidth = 1.2) +
geom_point() +
ylim(0,100) +
scale_color_manual(values = col_val) +
scale_x_discrete(labels = function(x) str_wrap(x, width = 5)) +
scale_linetype_manual(values = lines,
guide = guide_legend(override.aes = list(linetype = "solid",
shape = rep(NA, length(lines))) )) +
theme_classic() +
theme(axis.title = element_text(size=14),
axis.text = element_text(size=10),
legend.position = c(0.35, 0.25),
panel.grid = element_blank(),
strip.background = element_blank()) +
labs(x = "Time Window",
y = "Specificity",
title = "" )
# combine plots (uses patchwork)
p1 + p2
}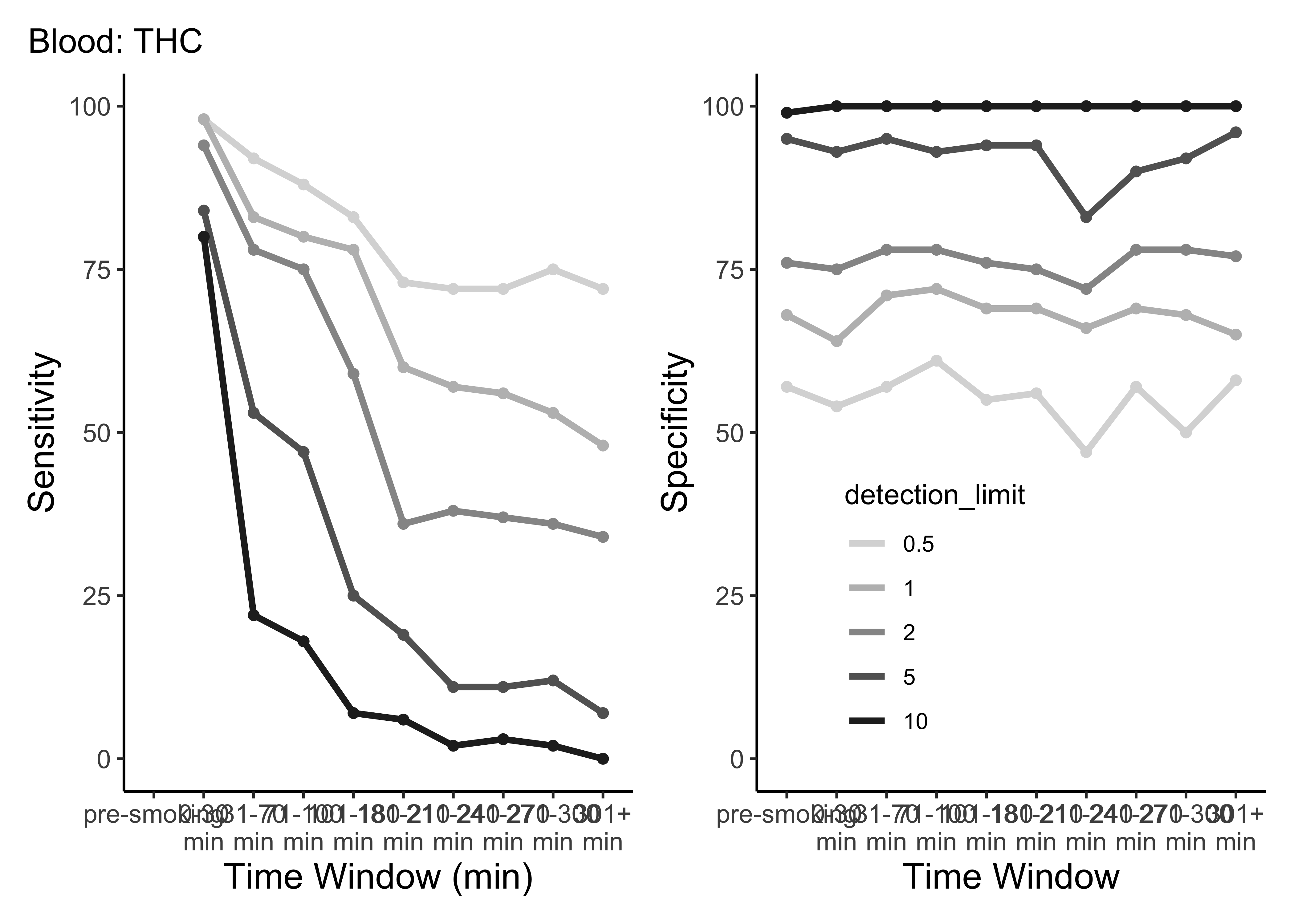
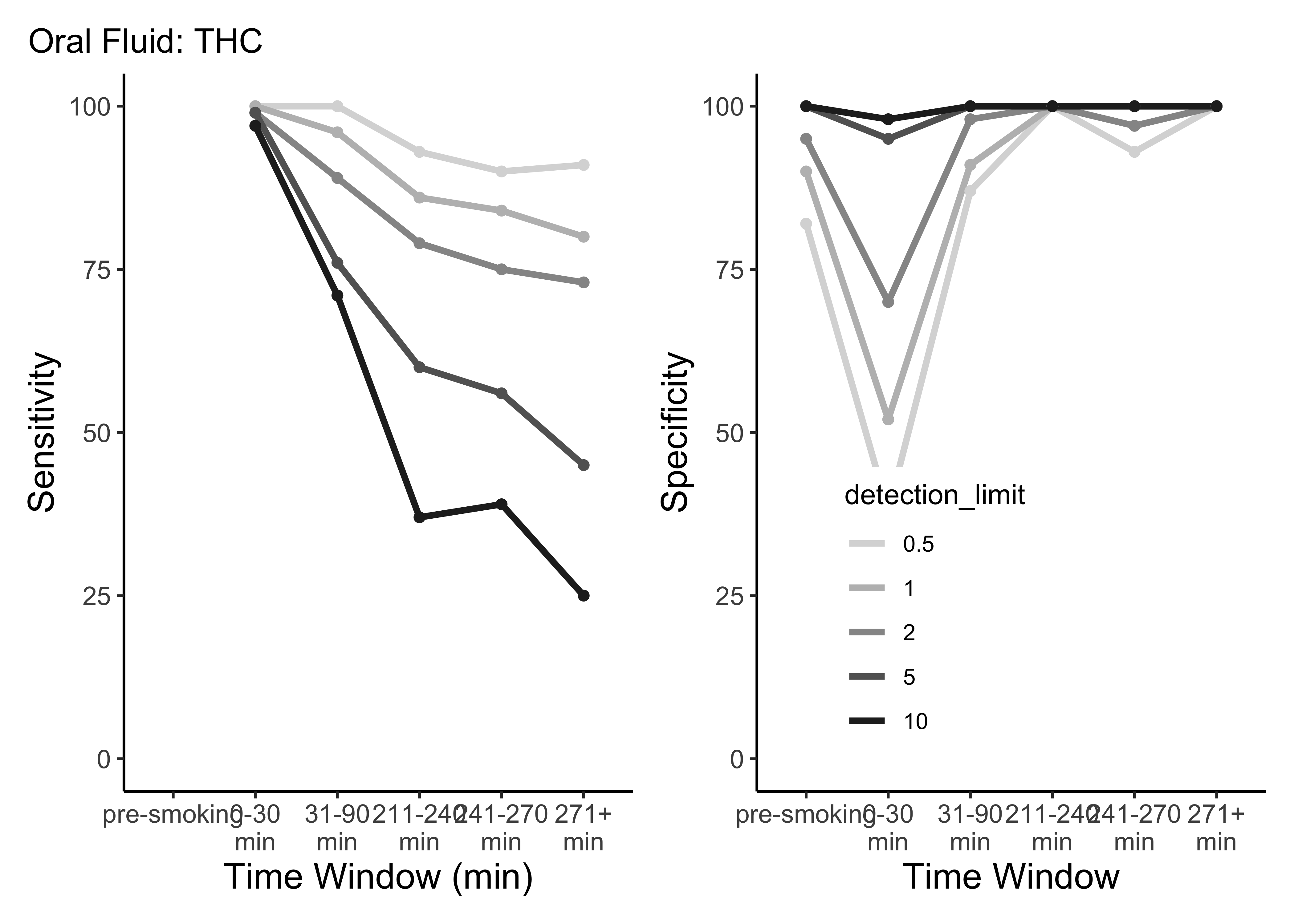
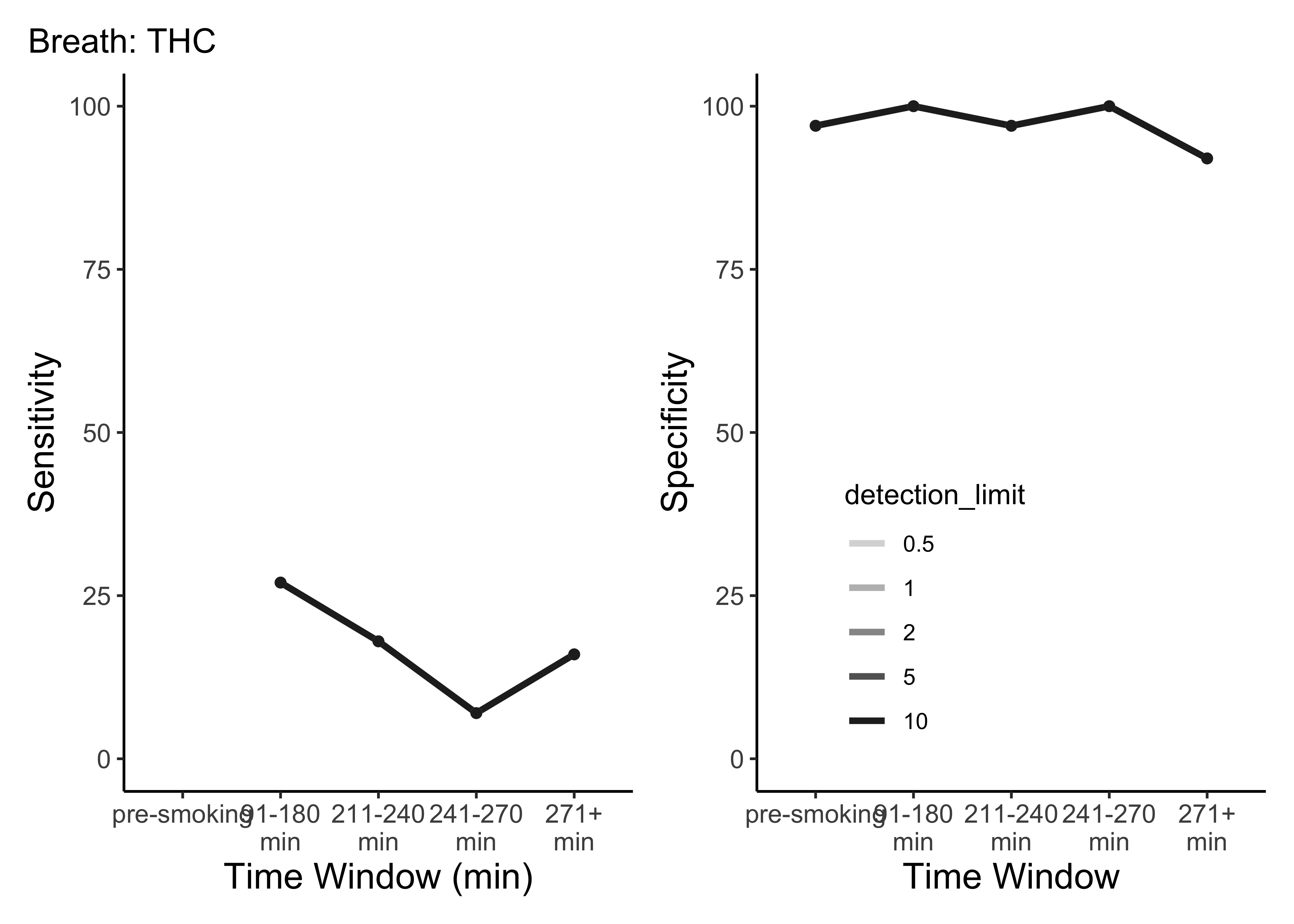
- This is only THC
- For five semi-random cutoffs
- There are other compounds and other cutoffs to consider
Recap
- Can you explain/describe the plots generated in the context of these data?
- Can you generate EDA plots of your own for these data
- Can you understand/work through the more complicated code provided (even if you couldn’t have come up with it on your own)
- Can you describe sensitivity? Specificity?
- Can you explain how TP, TN, FP, and FN were calculated/defined in this experiment?
- Can you describe the code used to carry out the calculations?
- Can you interpret the results from these data?
![]()