10-cs02-eda
2024-11-07
Feature Correlation
Why do we care if variables in our dataset are correlated?
- we don’t want to include redundant variables
- can add unnecessary noise to our algorithm causing a reduction in prediction accuracy
- can cause our algorithm to be slower
- can also make it difficult to interpret what variables are actually predictive
Taking a look at our numeric variables…
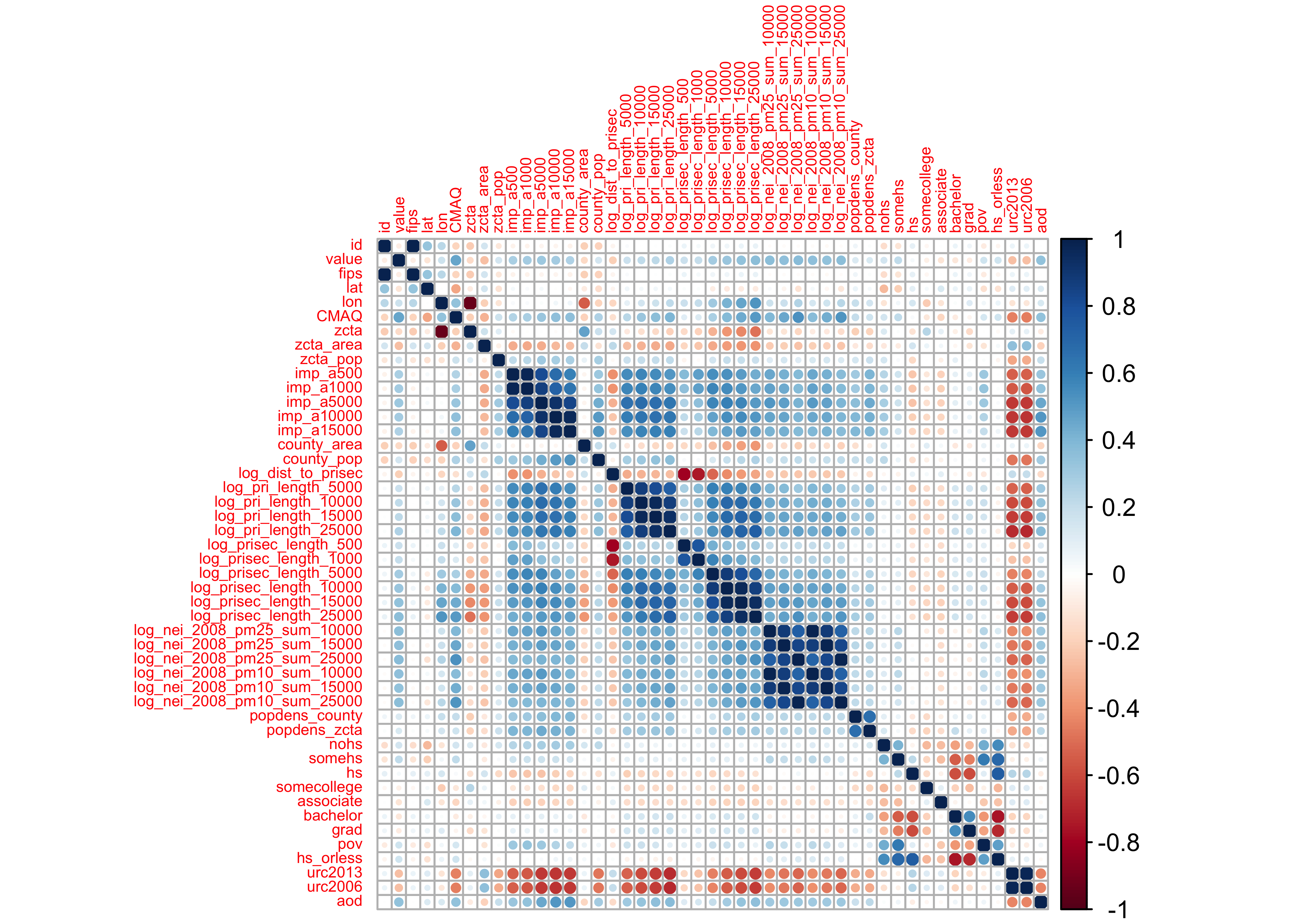
- deep blue | strongly, positively correlated
- deep red | strongly, negatively correlated
If we don’t care about direction, but only strength…and using hierarchical clustering:
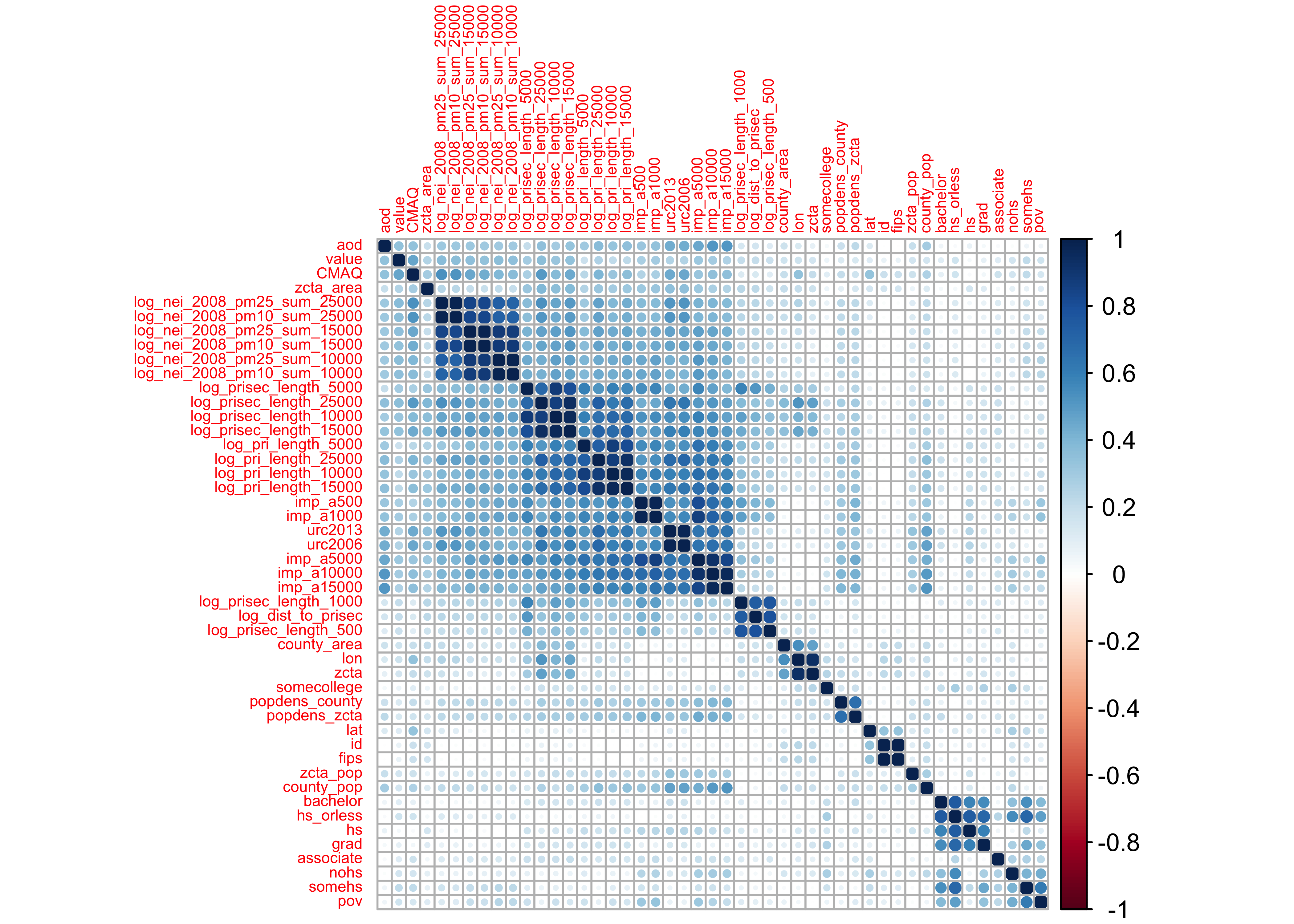
Observations:
- development variables (
imp), road density (pri), and the emission (nei) variables all seem to be correlated with their group - none of the predictors are correlated with
value(our outcome)
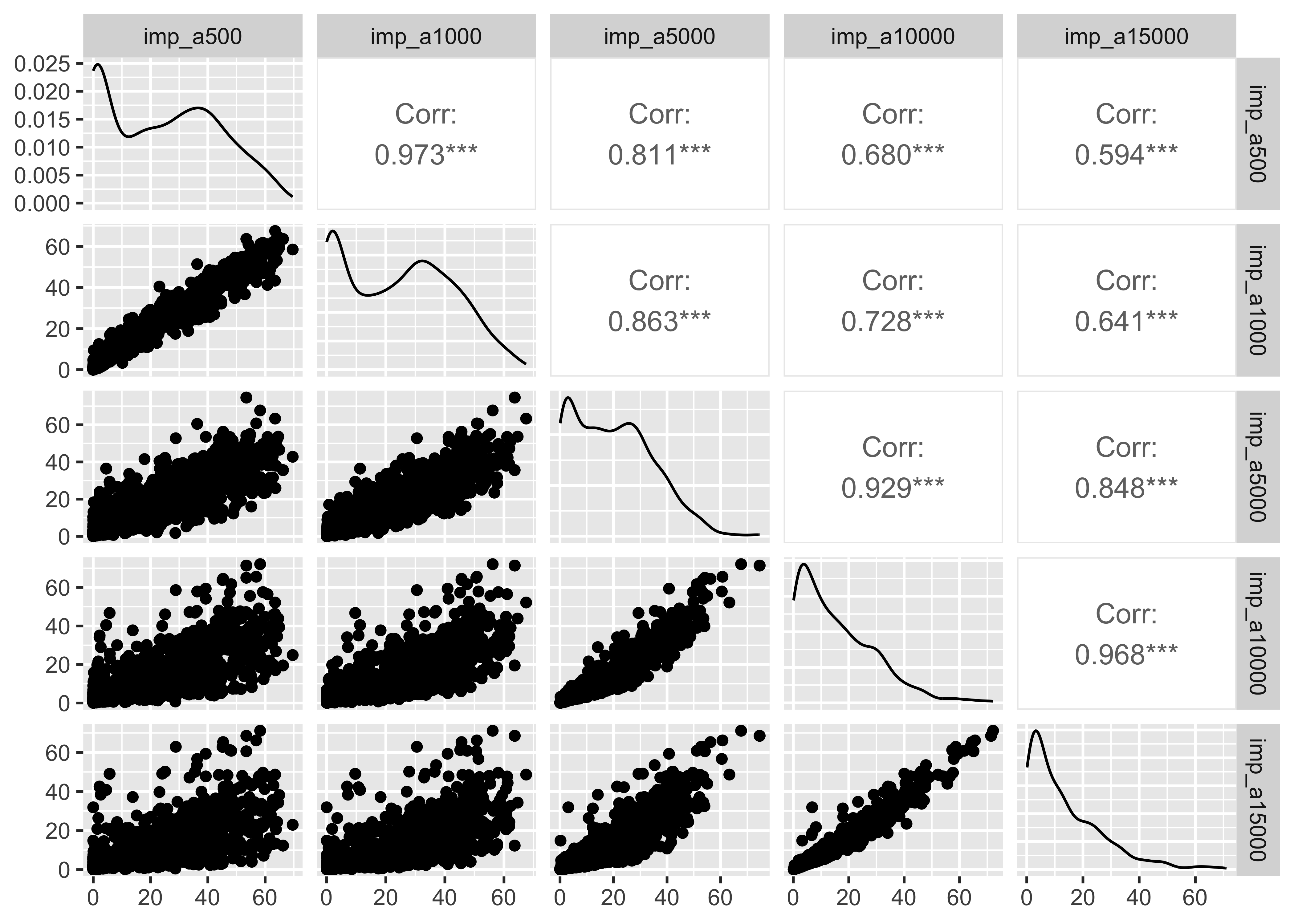
Development (imp)
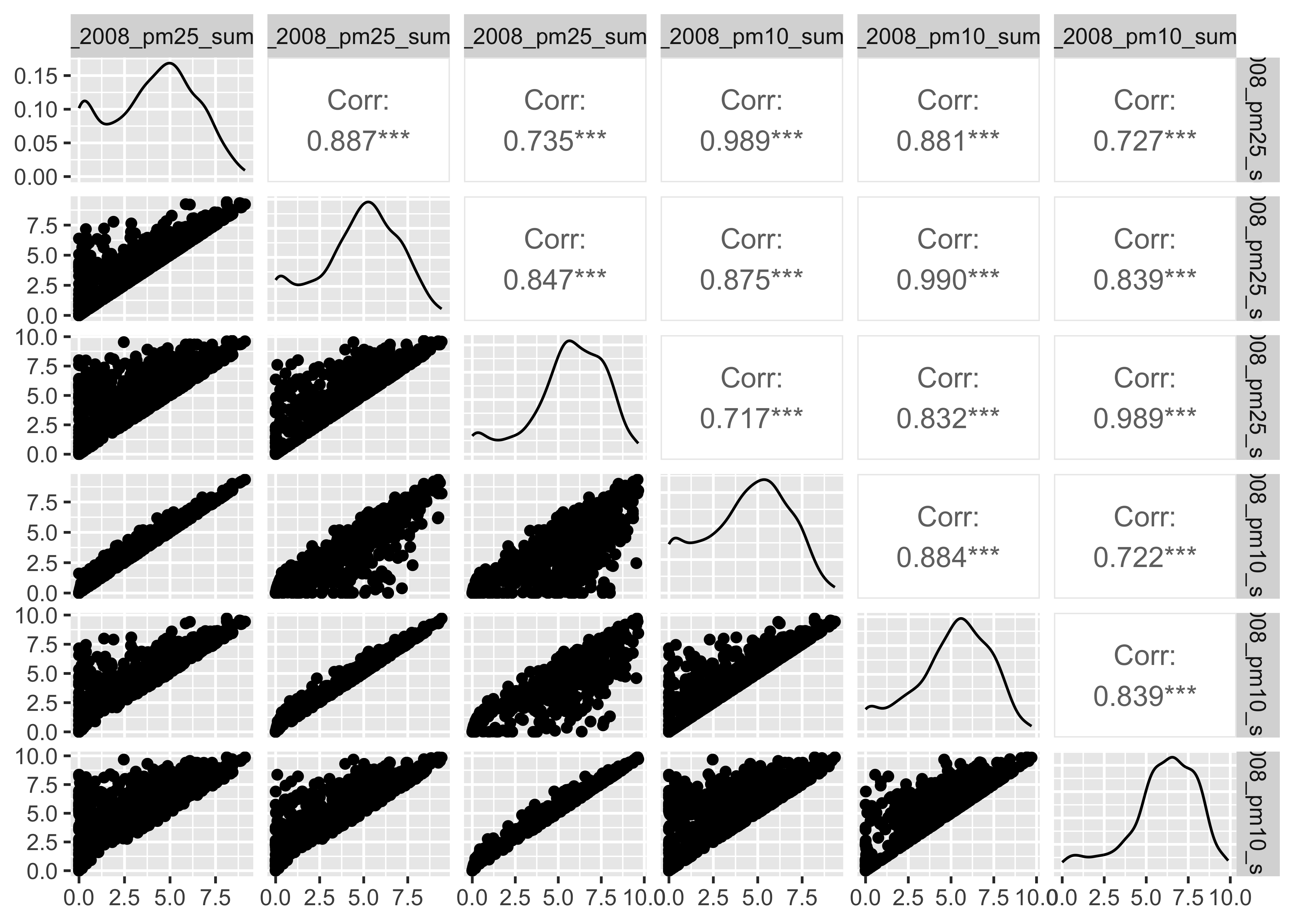
Emmissoins (nei)
Road Density (pri)
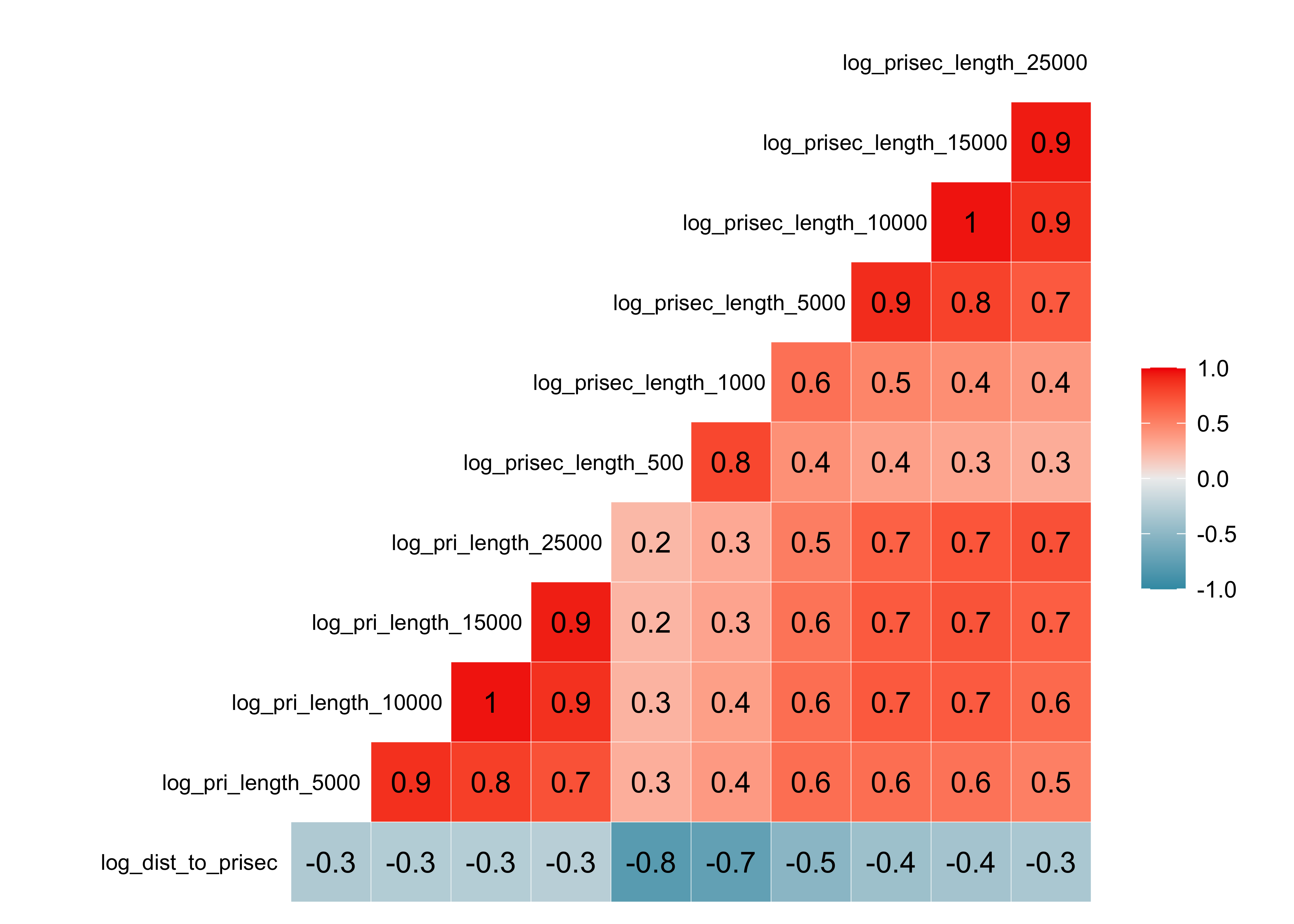
Warning: colors are reversed from above. If included in final report, you’d want consistency.
Are the categories correlated with one another?
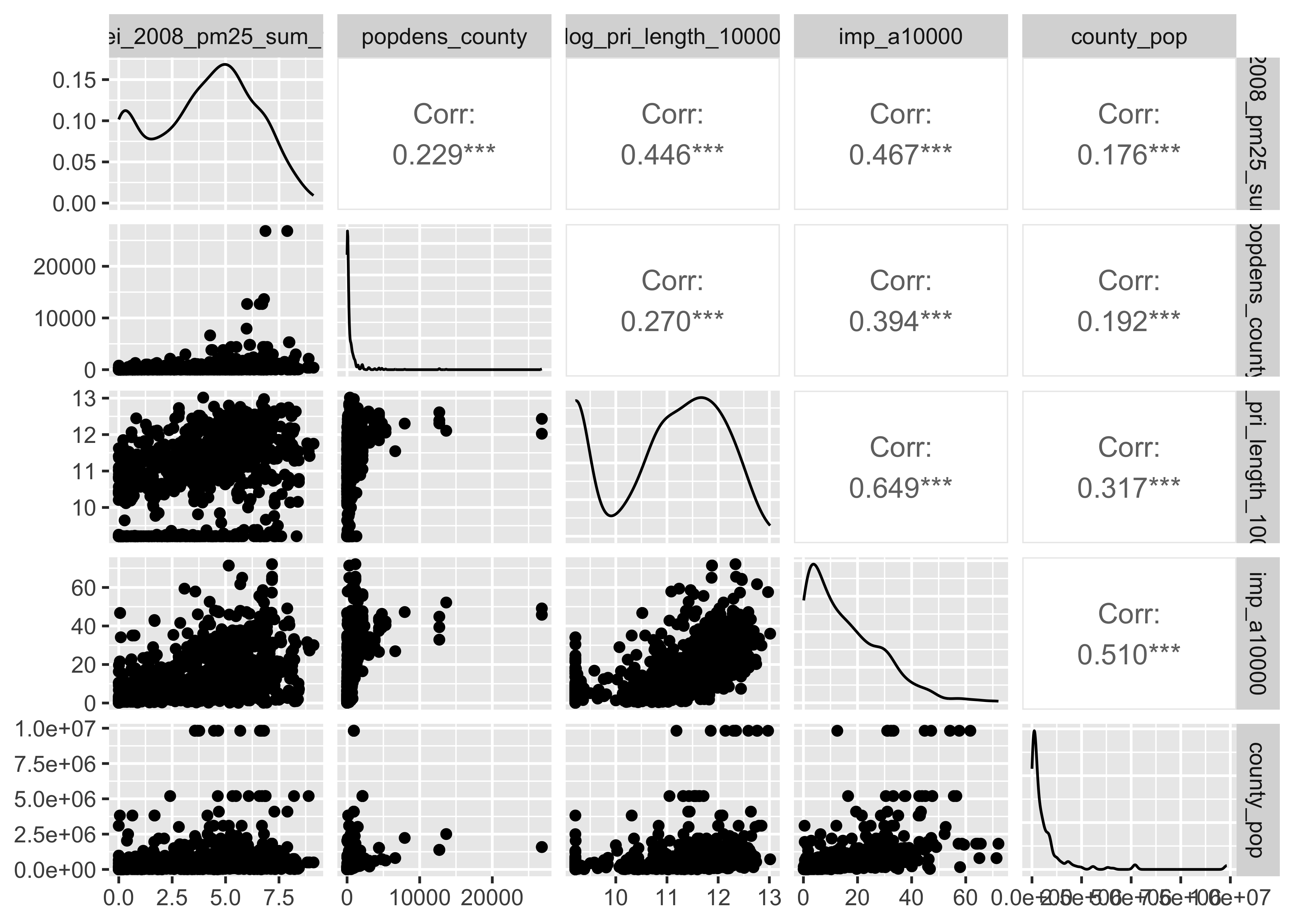
Reminder:
- log_nei_2008_pm25_sum_10000 | Tons of emissions from major sources data base (annual data) sum of all sources within a circle with a radius of 10000 meters of distance around the monitor (Natural log)
- popdens_county | Population density (number of people per kilometer squared area of the county)
- log_pri_length_10000 | Count of primary road length in meters in a circle with a radius of 10000 meters around the monitor (Natural log)
– Highways only
- imp_a10000 | Impervious surface measure
– Within a circle with a radius of 10000 meters around the monitor
- county_pop | Population of the county of the monitor
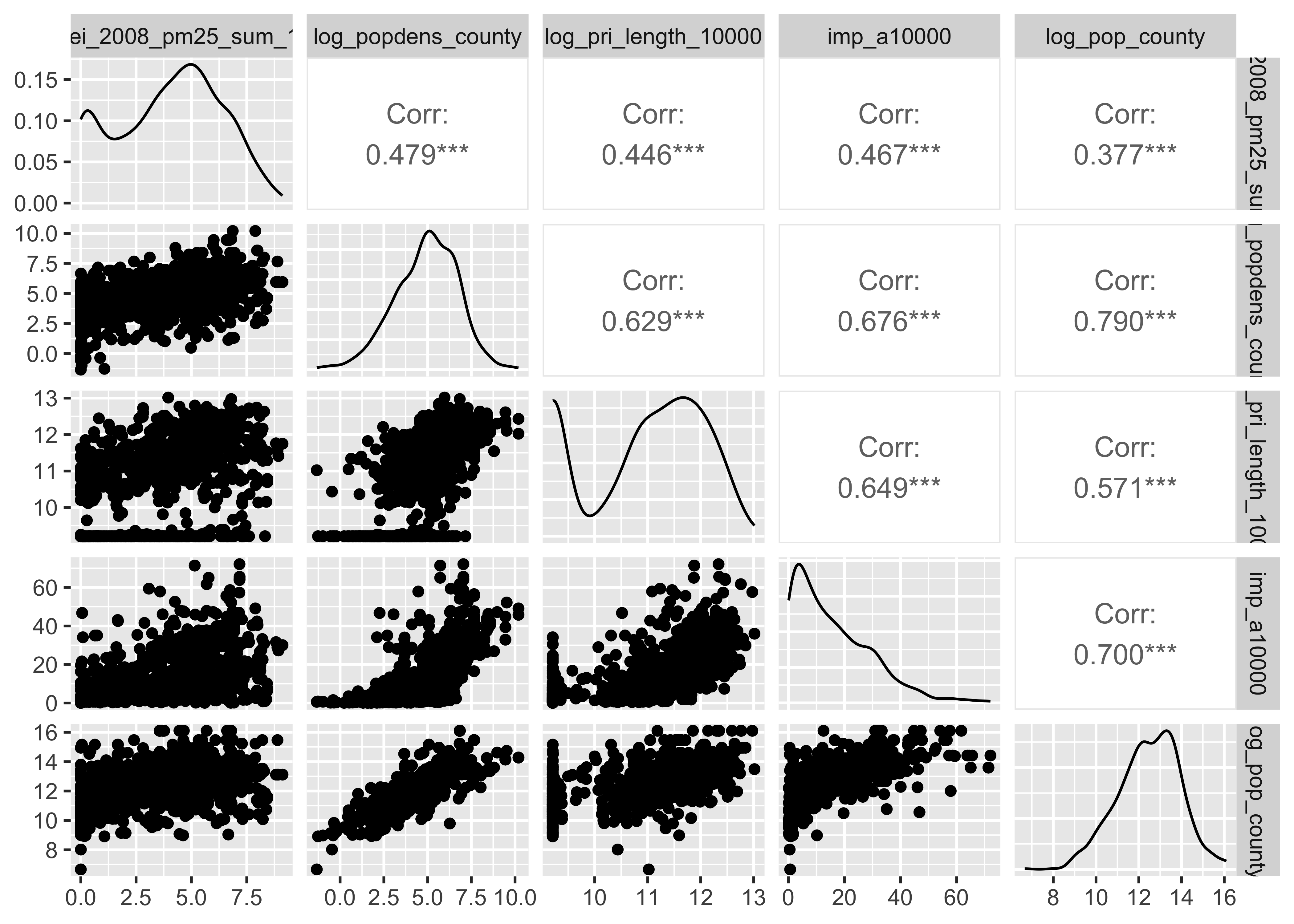
Log-transforming right-skewed data
Your Turn
💪 Try to learn at least three things about the data that we haven’t yet discussed now on your own.
Add your EDA to a Padlet https://padlet.com/shannon0ellis/cs02_eda
![]()