13-cs02-analysis
2024-11-19
Building our tidymodels knowledge:
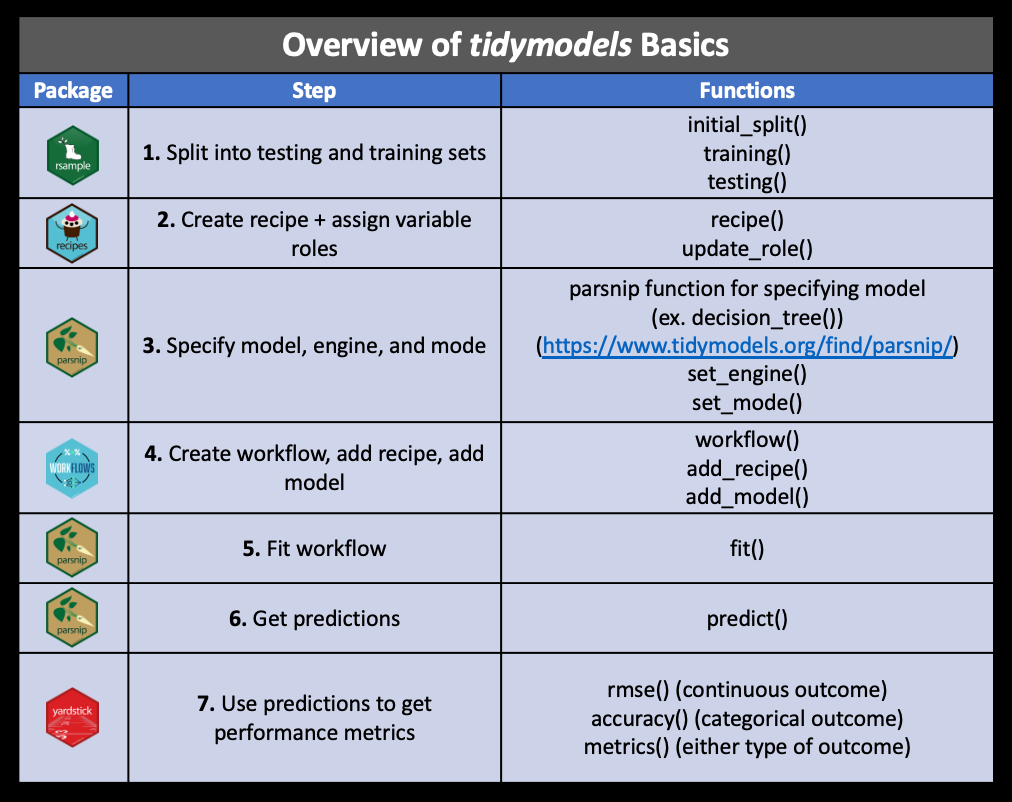
Data Splitting
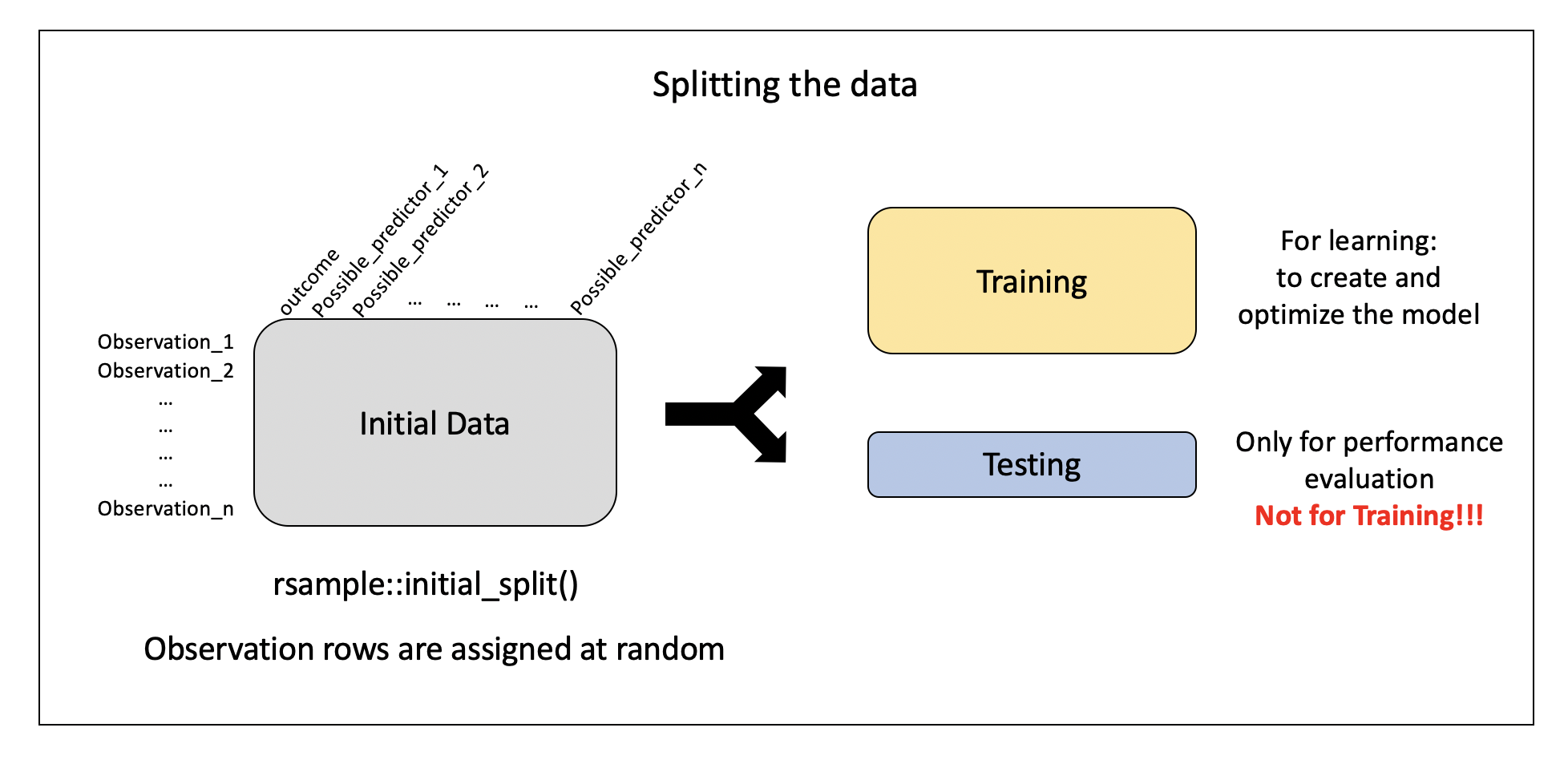
Specify the split:
<Training/Testing/Total>
<584/292/876>set.seed<- ensures we all get the exact same random split- output displayed:
<training data sample number, testing data sample number, original sample number>
More on how people decide what proportions to use for data splitting here
Pre-processing: recipe() + bake()
Need to:
- specify predictors vs. outcome
- scale variables
- remove redundant variables (feature engineering)
recipe provides a standardized format for a sequence of steps for pre-processing the data
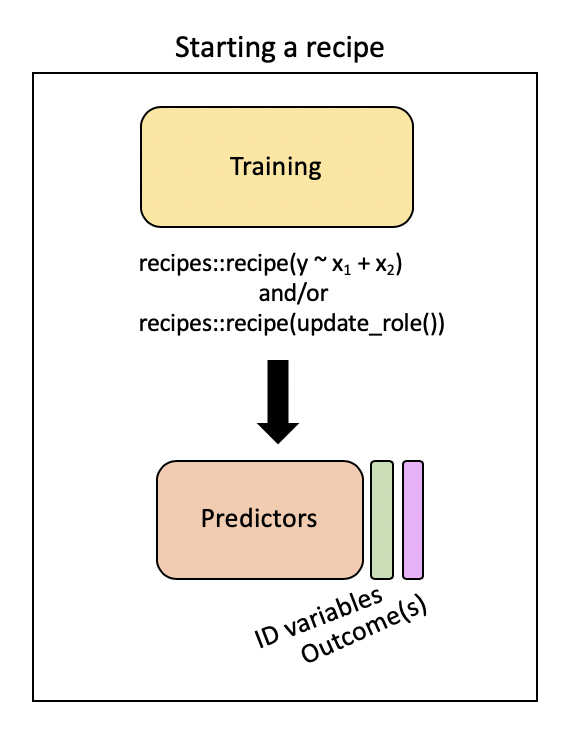
Step 2: Pre-process with step*()
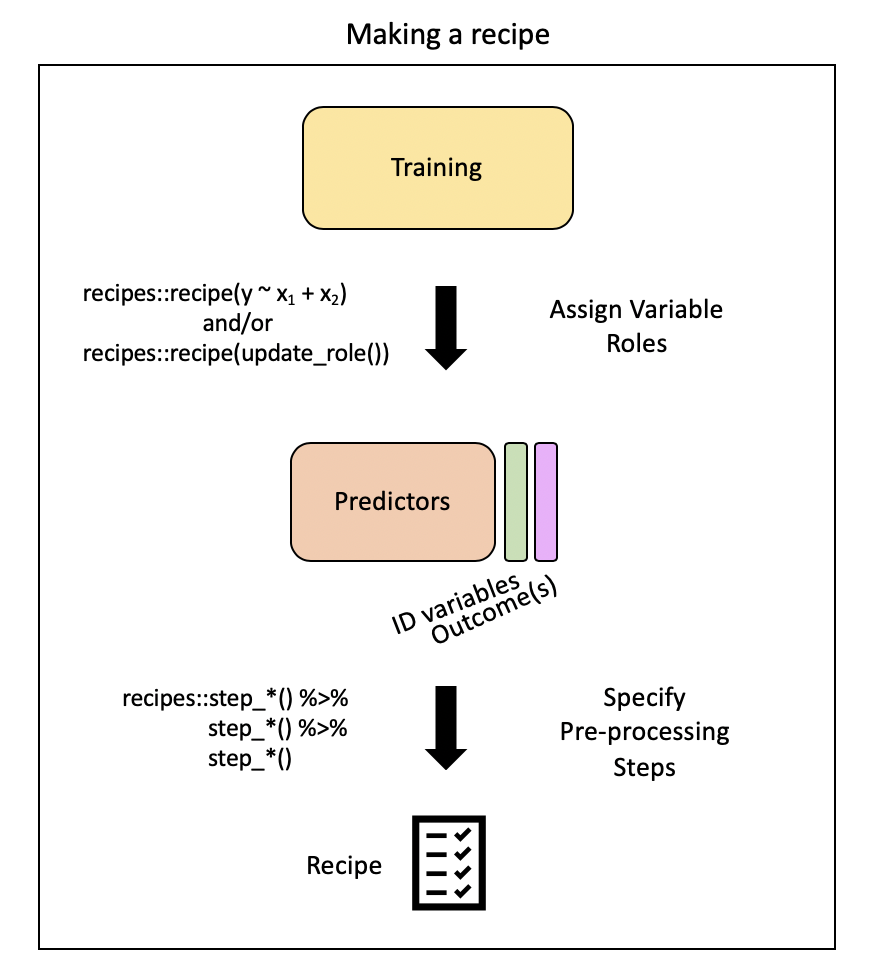
Step 4: Extract pre-processed training data using bake()
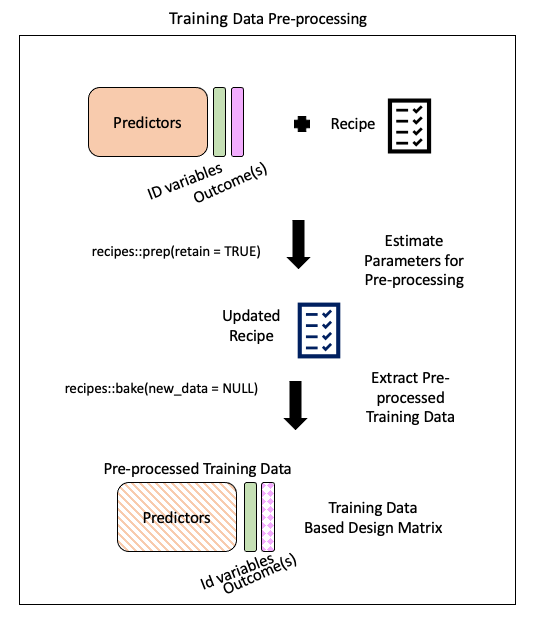
bake(): apply our modeling steps (in this case just pre-processing on the training data) and see what it would do the data
Rows: 584
Columns: 37
$ id <fct> 18003.0004, 55041.0007, 6065.1003, 39009.0…
$ value <dbl> 11.699065, 6.956780, 13.289744, 10.742000,…
$ fips <fct> 18003, 55041, 6065, 39009, 39061, 24510, 6…
$ lat <dbl> 41.09497, 45.56300, 33.94603, 39.44217, 39…
$ lon <dbl> -85.10182, -88.80880, -117.40063, -81.9088…
$ CMAQ <dbl> 10.383231, 3.411247, 11.404085, 7.971165, …
$ zcta_area <dbl> 16696709, 370280916, 41957182, 132383592, …
$ zcta_pop <dbl> 21306, 4141, 44001, 1115, 6566, 934, 41192…
$ imp_a500 <dbl> 28.9783737, 0.0000000, 30.3901384, 0.00000…
$ imp_a15000 <dbl> 13.0547959, 0.3676404, 23.7457506, 0.33079…
$ county_area <dbl> 1702419942, 2626421270, 18664696661, 13043…
$ county_pop <dbl> 355329, 9304, 2189641, 64757, 802374, 6209…
$ log_dist_to_prisec <dbl> 6.621891, 8.415468, 7.419762, 6.344681, 5.…
$ log_pri_length_5000 <dbl> 8.517193, 8.517193, 10.150514, 8.517193, 9…
$ log_pri_length_25000 <dbl> 12.77378, 10.16440, 13.14450, 10.12663, 13…
$ log_prisec_length_500 <dbl> 6.214608, 6.214608, 6.214608, 6.214608, 7.…
$ log_prisec_length_1000 <dbl> 9.240294, 7.600902, 7.600902, 8.793450, 8.…
$ log_prisec_length_5000 <dbl> 11.485093, 9.425537, 10.155961, 10.562382,…
$ log_prisec_length_10000 <dbl> 12.75582, 11.44833, 11.59563, 11.69093, 12…
$ log_nei_2008_pm10_sum_10000 <dbl> 4.91110140, 3.86982666, 4.03184660, 0.0000…
$ log_nei_2008_pm10_sum_15000 <dbl> 5.399131, 3.883689, 5.459257, 0.000000, 6.…
$ log_nei_2008_pm10_sum_25000 <dbl> 5.816047, 3.887264, 6.884537, 3.765635, 6.…
$ popdens_county <dbl> 208.719947, 3.542463, 117.314577, 49.64834…
$ popdens_zcta <dbl> 1276.059851, 11.183401, 1048.711994, 8.422…
$ nohs <dbl> 4.3, 5.1, 3.7, 4.8, 2.1, 0.0, 2.5, 7.7, 0.…
$ somehs <dbl> 6.7, 10.4, 5.9, 11.5, 10.5, 0.0, 4.3, 7.5,…
$ hs <dbl> 31.7, 40.3, 17.9, 47.3, 30.0, 0.0, 17.8, 2…
$ somecollege <dbl> 27.2, 24.1, 26.3, 20.0, 27.1, 0.0, 26.1, 2…
$ associate <dbl> 8.2, 7.4, 8.3, 3.1, 8.5, 71.4, 13.2, 7.6, …
$ bachelor <dbl> 15.0, 8.6, 20.2, 9.8, 14.2, 0.0, 23.4, 17.…
$ grad <dbl> 6.8, 4.2, 17.7, 3.5, 7.6, 28.6, 12.6, 12.3…
$ pov <dbl> 13.500, 18.900, 6.700, 14.400, 12.500, 3.5…
$ hs_orless <dbl> 42.7, 55.8, 27.5, 63.6, 42.6, 0.0, 24.6, 3…
$ urc2006 <dbl> 3, 6, 1, 5, 1, 1, 2, 1, 2, 6, 4, 4, 4, 4, …
$ aod <dbl> 54.11111, 31.16667, 83.12500, 33.36364, 50…
$ state_California <dbl> 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, …
$ city_Not.in.a.city <dbl> 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, …new_data = NULLspecifies that we’re not (yet) looking at our testing data- We only have 36 variables (33 predictors + 2 id variables + outcome)
- categorical variables (
state) are gone (one-hot encoding) state_Californiaremains - only state with nonzero variance (largest # of monitors)
Step 5: Extract pre-processed testing data using bake()
bake()takes a trained recipe and applies the operations to a data set to create a design matrix. For example: it applies the centering to new data sets using these means used to create the recipe. -tidymodelsdocumentation
Typically, you want to avoid using your testing data…but our data set is not that large and NA values in our testing dataset could cause issues later on.
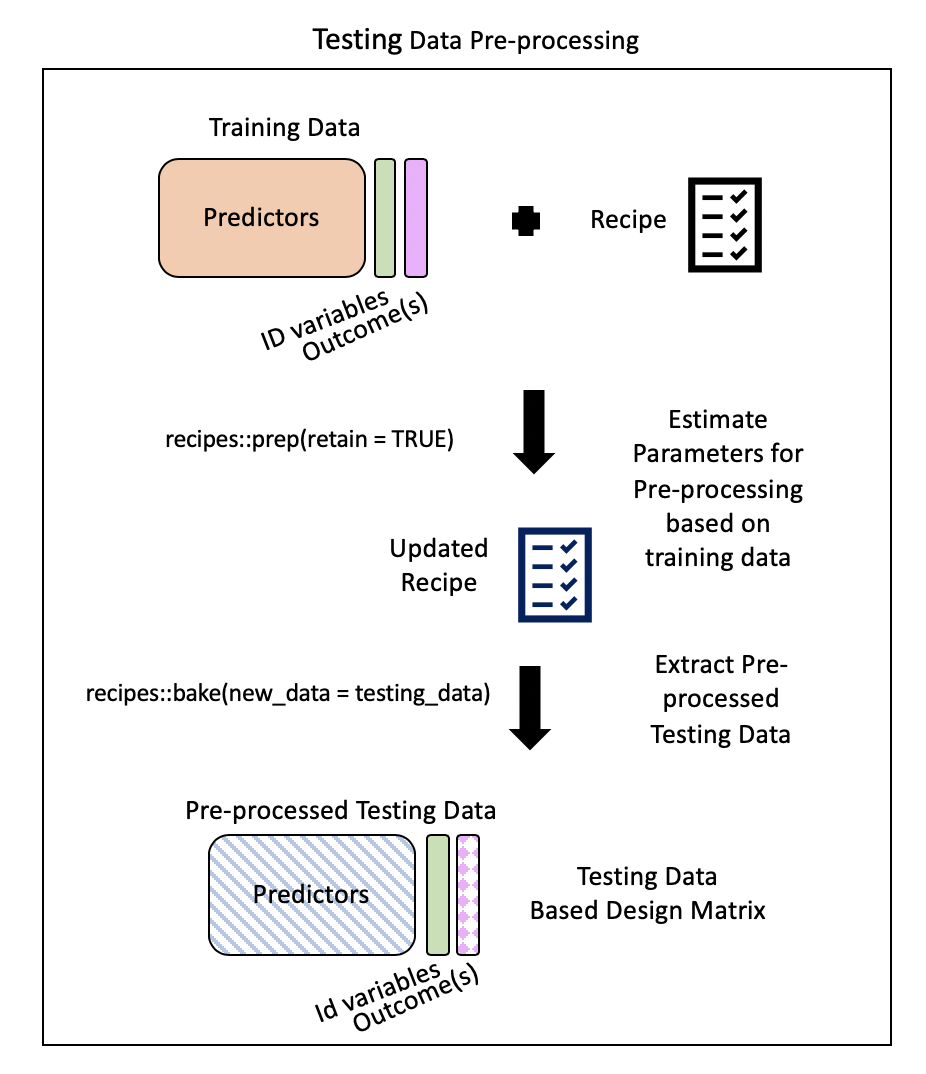
Rows: 292
Columns: 37
$ id <fct> 1033.1002, 1055.001, 1069.0003, 1073.0023,…
$ value <dbl> 11.212174, 12.375394, 10.508850, 15.591017…
$ fips <fct> 1033, 1055, 1069, 1073, 1073, 1073, 1073, …
$ lat <dbl> 34.75878, 33.99375, 31.22636, 33.55306, 33…
$ lon <dbl> -87.65056, -85.99107, -85.39077, -86.81500…
$ CMAQ <dbl> 9.402679, 9.241744, 9.121892, 10.235612, 1…
$ zcta_area <dbl> 16716984, 154069359, 162685124, 26929603, …
$ zcta_pop <dbl> 9042, 20045, 30217, 9010, 16140, 3699, 137…
$ imp_a500 <dbl> 19.17301038, 16.49307958, 19.13927336, 41.…
$ imp_a15000 <dbl> 5.2472094, 5.1612102, 4.7401296, 17.452484…
$ county_area <dbl> 1534877333, 1385618994, 1501737720, 287819…
$ county_pop <dbl> 54428, 104430, 101547, 658466, 658466, 194…
$ log_dist_to_prisec <dbl> 5.760131, 5.261457, 7.112373, 6.600958, 6.…
$ log_pri_length_5000 <dbl> 8.517193, 9.066563, 8.517193, 11.156977, 1…
$ log_pri_length_25000 <dbl> 10.15769, 12.01356, 10.12663, 12.98762, 12…
$ log_prisec_length_500 <dbl> 8.611945, 8.740680, 6.214608, 6.214608, 6.…
$ log_prisec_length_1000 <dbl> 9.735569, 9.627898, 7.600902, 9.075921, 8.…
$ log_prisec_length_5000 <dbl> 11.770407, 11.728889, 12.298627, 12.281645…
$ log_prisec_length_10000 <dbl> 12.840663, 12.768279, 12.994141, 13.278416…
$ log_nei_2008_pm10_sum_10000 <dbl> 6.69187313, 4.43719884, 0.92888890, 8.2097…
$ log_nei_2008_pm10_sum_15000 <dbl> 6.70127741, 4.46267932, 3.67473904, 8.6488…
$ log_nei_2008_pm10_sum_25000 <dbl> 7.148858, 4.678311, 3.744629, 8.858019, 8.…
$ popdens_county <dbl> 35.460814, 75.367038, 67.619664, 228.77763…
$ popdens_zcta <dbl> 540.8870404, 130.1037411, 185.7391706, 334…
$ nohs <dbl> 7.3, 4.3, 5.8, 7.1, 2.7, 11.1, 9.7, 3.0, 8…
$ somehs <dbl> 15.8, 13.3, 11.6, 17.1, 6.6, 11.6, 21.6, 1…
$ hs <dbl> 30.6, 27.8, 29.8, 37.2, 30.7, 46.0, 39.3, …
$ somecollege <dbl> 20.9, 29.2, 21.4, 23.5, 25.7, 17.2, 21.6, …
$ associate <dbl> 7.6, 10.1, 7.9, 7.3, 8.0, 4.1, 5.2, 6.6, 4…
$ bachelor <dbl> 12.7, 10.0, 13.7, 5.9, 17.6, 7.1, 2.2, 7.8…
$ grad <dbl> 5.1, 5.4, 9.8, 2.0, 8.7, 2.9, 0.4, 4.2, 3.…
$ pov <dbl> 19.0, 8.8, 15.6, 25.5, 7.3, 8.1, 13.3, 23.…
$ hs_orless <dbl> 53.7, 45.4, 47.2, 61.4, 40.0, 68.7, 70.6, …
$ urc2006 <dbl> 4, 4, 4, 1, 1, 1, 2, 3, 3, 3, 2, 5, 4, 1, …
$ aod <dbl> 36.000000, 43.416667, 33.000000, 39.583333…
$ state_California <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ city_Not.in.a.city <dbl> NA, NA, NA, 0, 1, 1, 1, NA, NA, NA, 0, NA,…Hmm….lots of NAs now in city_Not.in.a.city
Likely b/c there are cities in our testing dataset that were not in our training dataset…
Step 4: Assess model fit
# A tibble: 36 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 2.94e+ 2 1.18e+ 2 2.49 0.0130
2 lat 3.26e- 2 2.28e- 2 1.43 0.153
3 lon 1.59e- 2 1.01e- 2 1.58 0.115
4 CMAQ 2.46e- 1 3.97e- 2 6.20 0.00000000108
5 zcta_area -3.43e-10 1.60e-10 -2.15 0.0320
6 zcta_pop 1.01e- 5 5.33e- 6 1.90 0.0578
7 imp_a500 5.06e- 3 7.42e- 3 0.683 0.495
8 imp_a15000 -3.07e- 3 1.16e- 2 -0.263 0.792
9 county_area -2.32e-11 1.97e-11 -1.18 0.238
10 county_pop -7.58e- 8 9.29e- 8 -0.815 0.415
# ℹ 26 more rows- We have fit our model on our training data
- We have created a model to predict values of air pollution based on the predictors that we have included
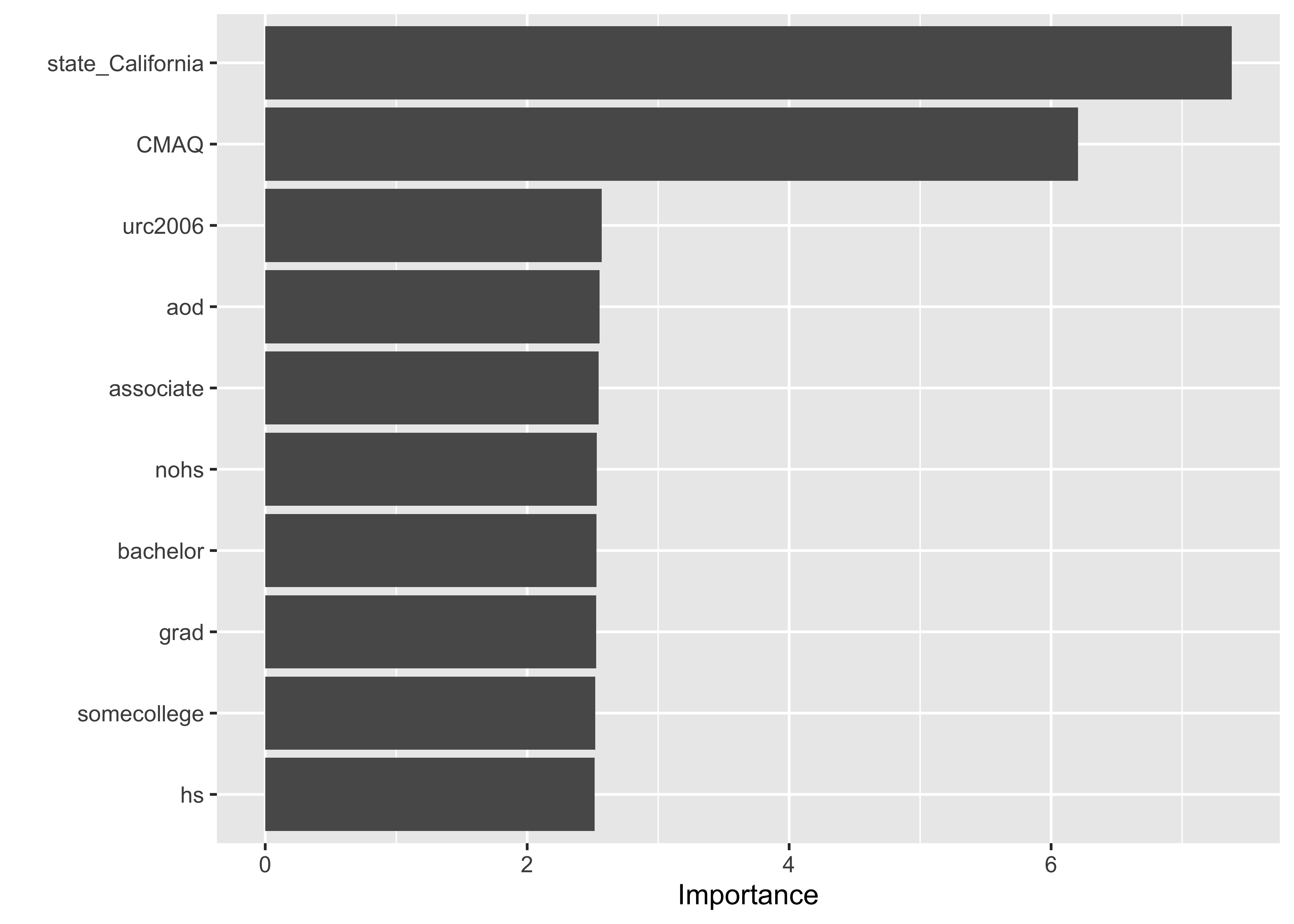
Understanding what variables are most important in our model…
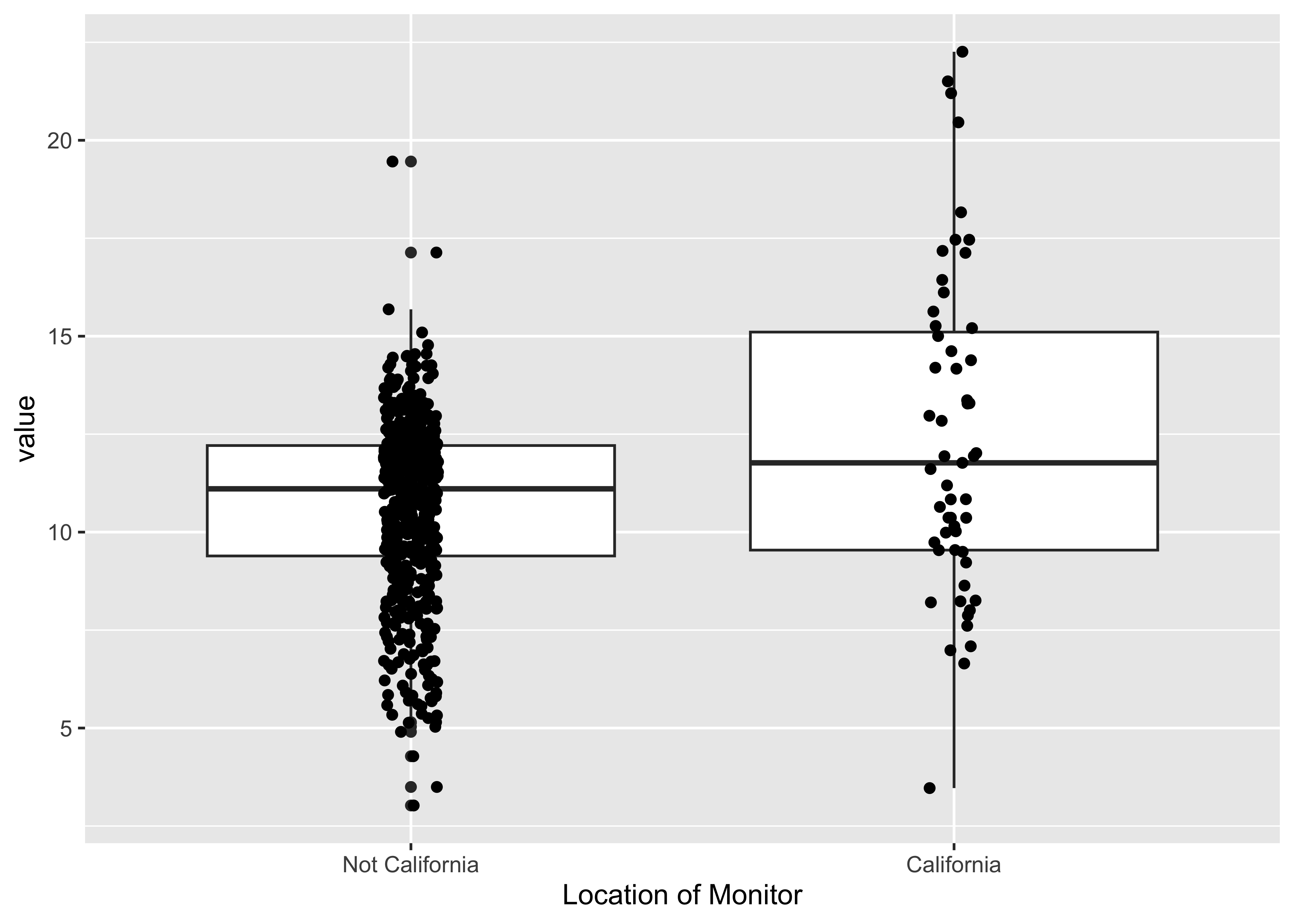
A closer look at monitors in CA:
Remember: machine learning (ML) as an optimization problem that tries to minimize the distance between our predicted outcome \(\hat{Y} = f(X)\) and actual outcome \(Y\) using our features (or predictor variables) \(X\) as input to a function \(f\) that we want to estimate.
\[d(Y - \hat{Y})\]
Let’s pull out our predicted outcome values \(\hat{Y} = f(X)\) from the models we fit (using different approaches).
wf_fit <- PM_wflow_fit |>
extract_fit_parsnip()
wf_fitted_values <-
broom::augment(wf_fit[["fit"]], data = baked_train) |>
select(value, .fitted:.std.resid)
head(wf_fitted_values)# A tibble: 6 × 6
value .fitted .hat .sigma .cooksd .std.resid
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 11.7 12.2 0.0370 2.05 0.0000648 -0.243
2 6.96 9.14 0.0496 2.05 0.00179 -1.09
3 13.3 12.6 0.0484 2.05 0.000151 0.322
4 10.7 10.4 0.0502 2.05 0.0000504 0.183
5 14.5 11.9 0.0243 2.05 0.00113 1.26
6 12.2 9.52 0.476 2.04 0.0850 1.81 Visualizing Model Performance
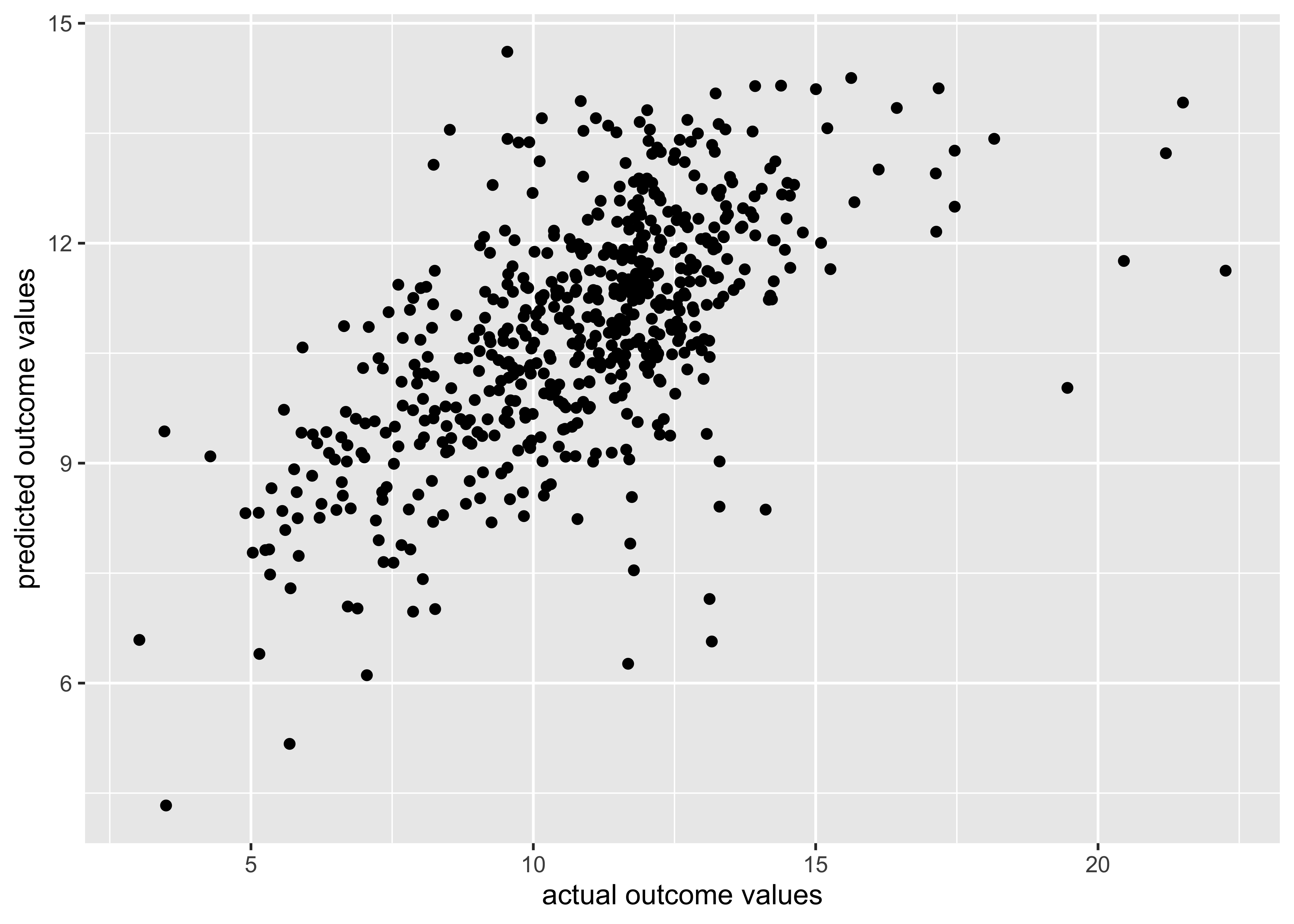
❓ What do you notice about/learn from these results?
Cross-Validation
Resampling + Re-partitioning:
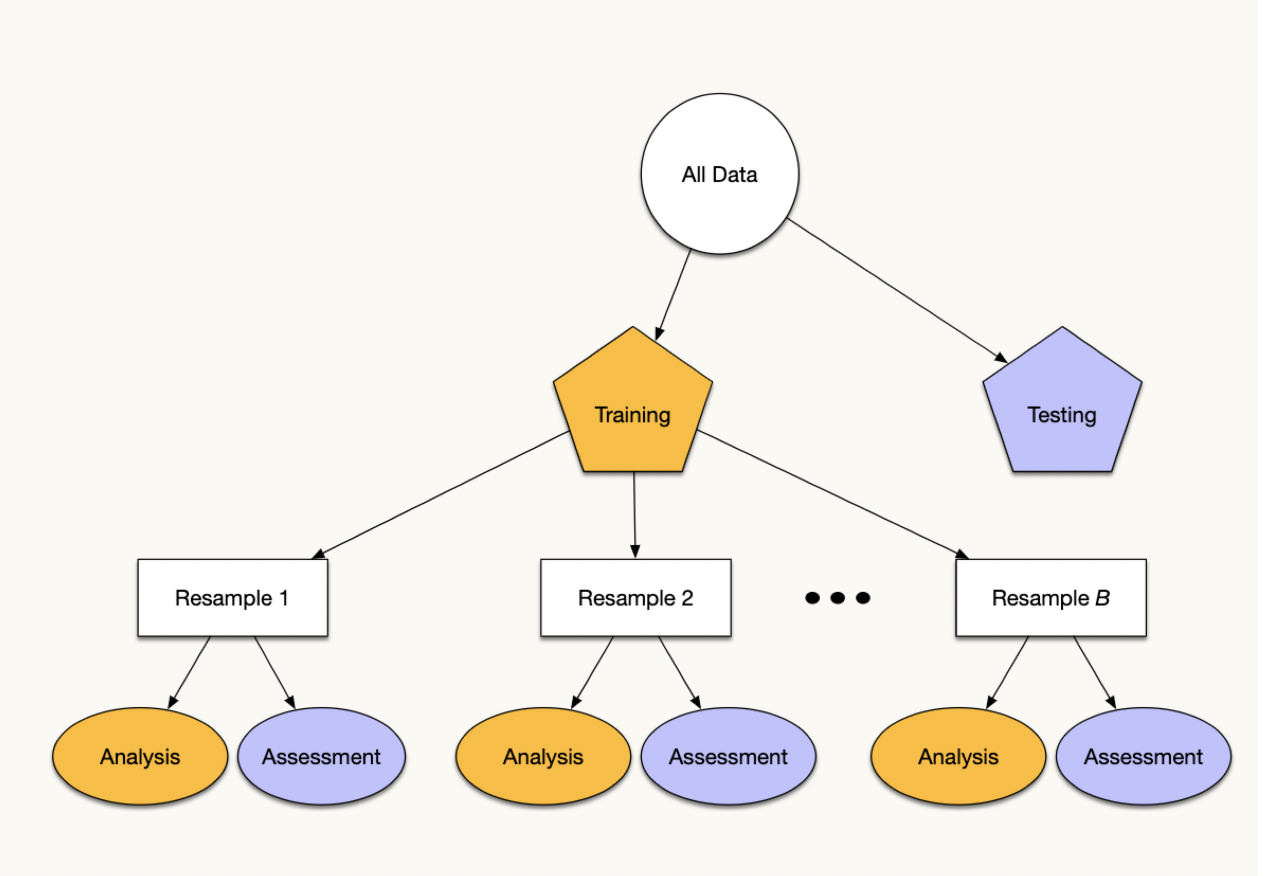
Preparing the data for cross-validation:
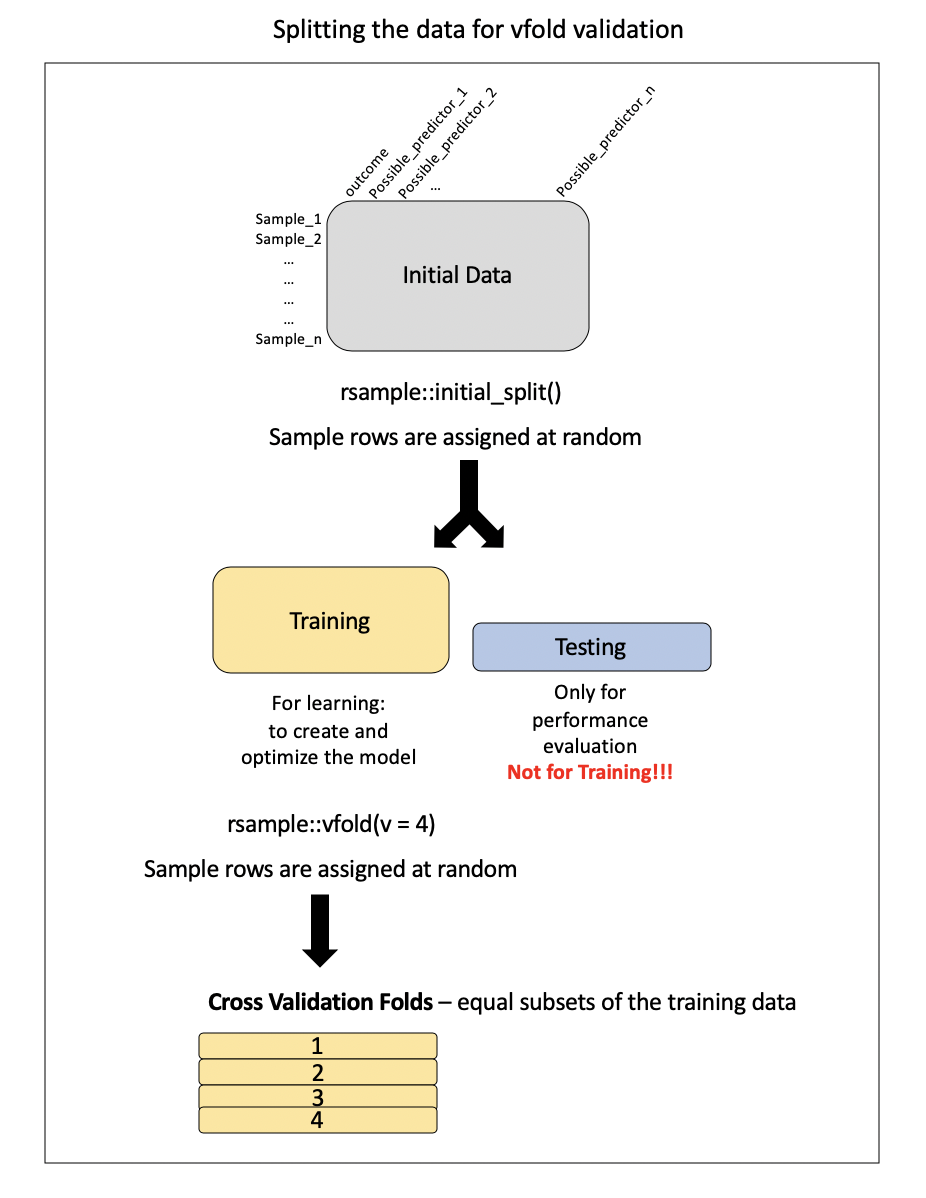
Note: this is called v-fold or k-fold CV
Implementing in rsample()
# 4-fold cross-validation
# A tibble: 4 × 2
splits id
<list> <chr>
1 <split [438/146]> Fold1
2 <split [438/146]> Fold2
3 <split [438/146]> Fold3
4 <split [438/146]> Fold4Visualizing this process:
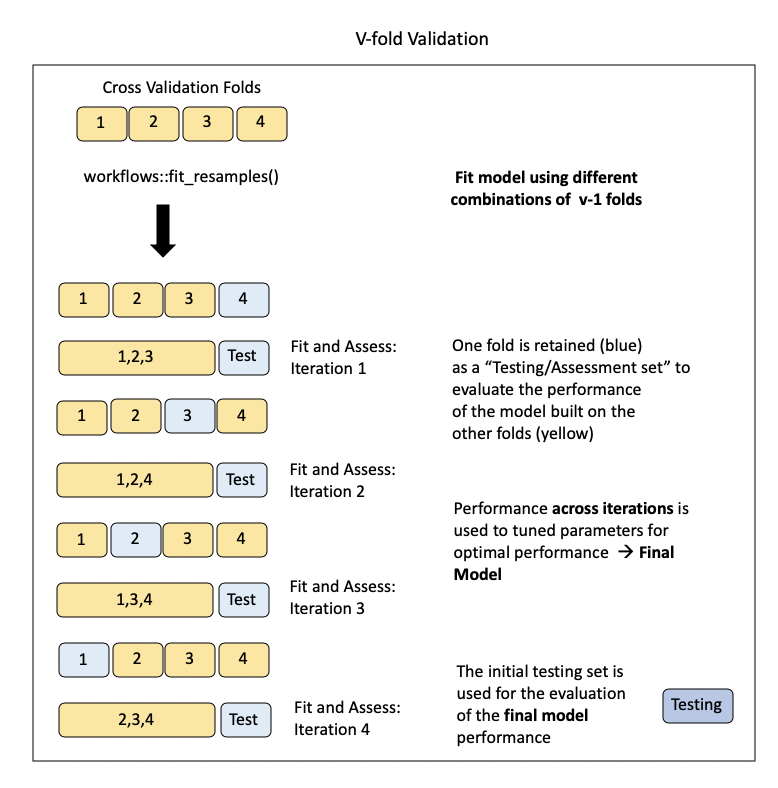
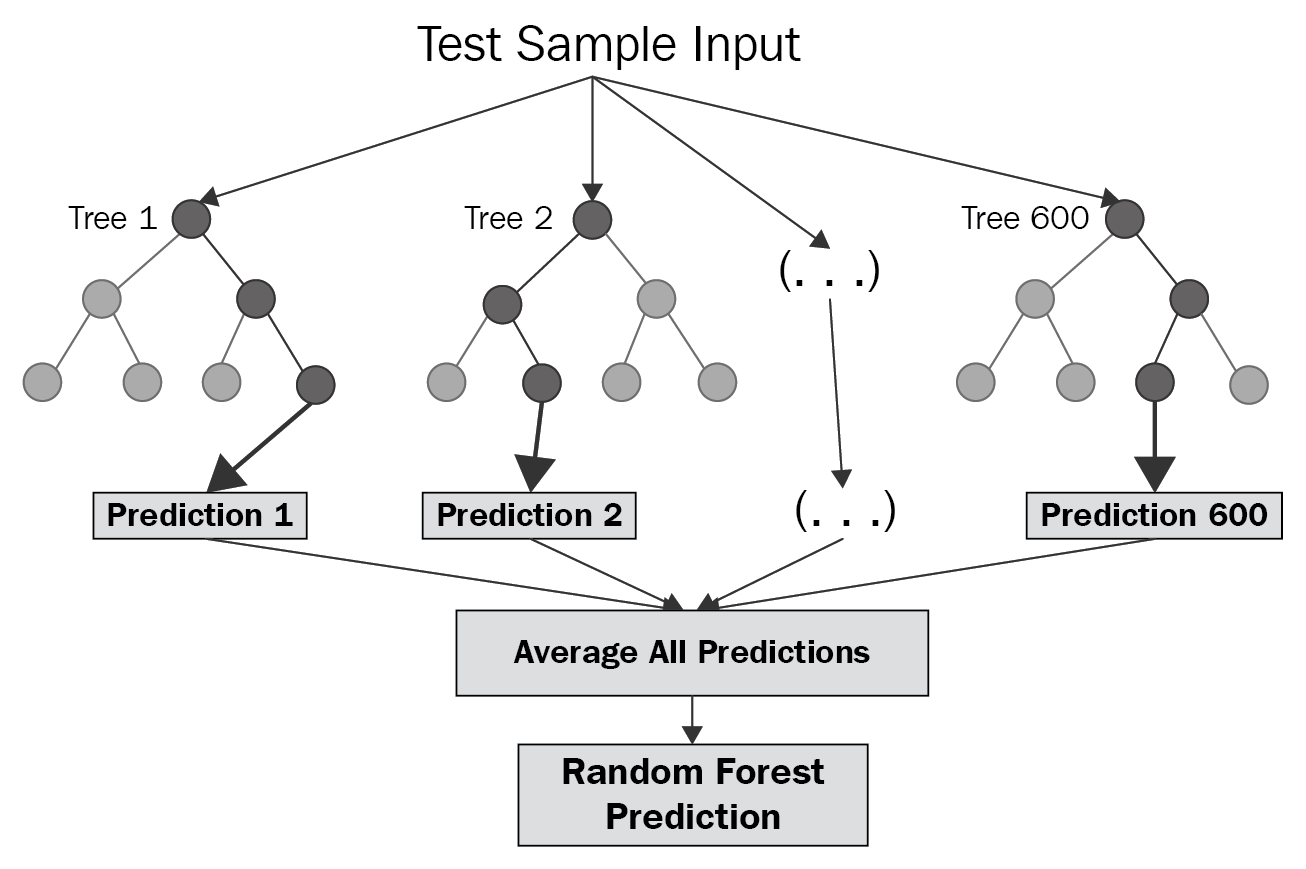
Random Forest
Fitting a different model…is based on a decision tree:
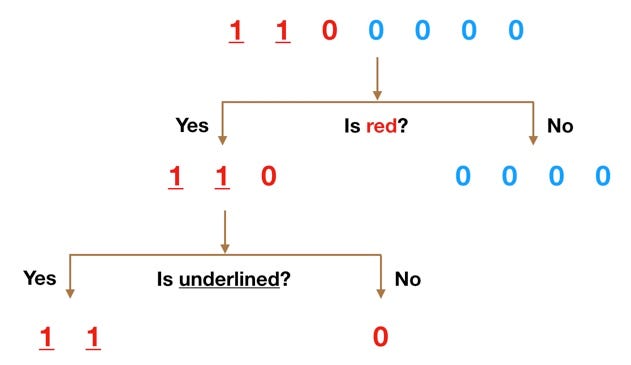
[source]
Visualizing a RF
Assess Feature Importance
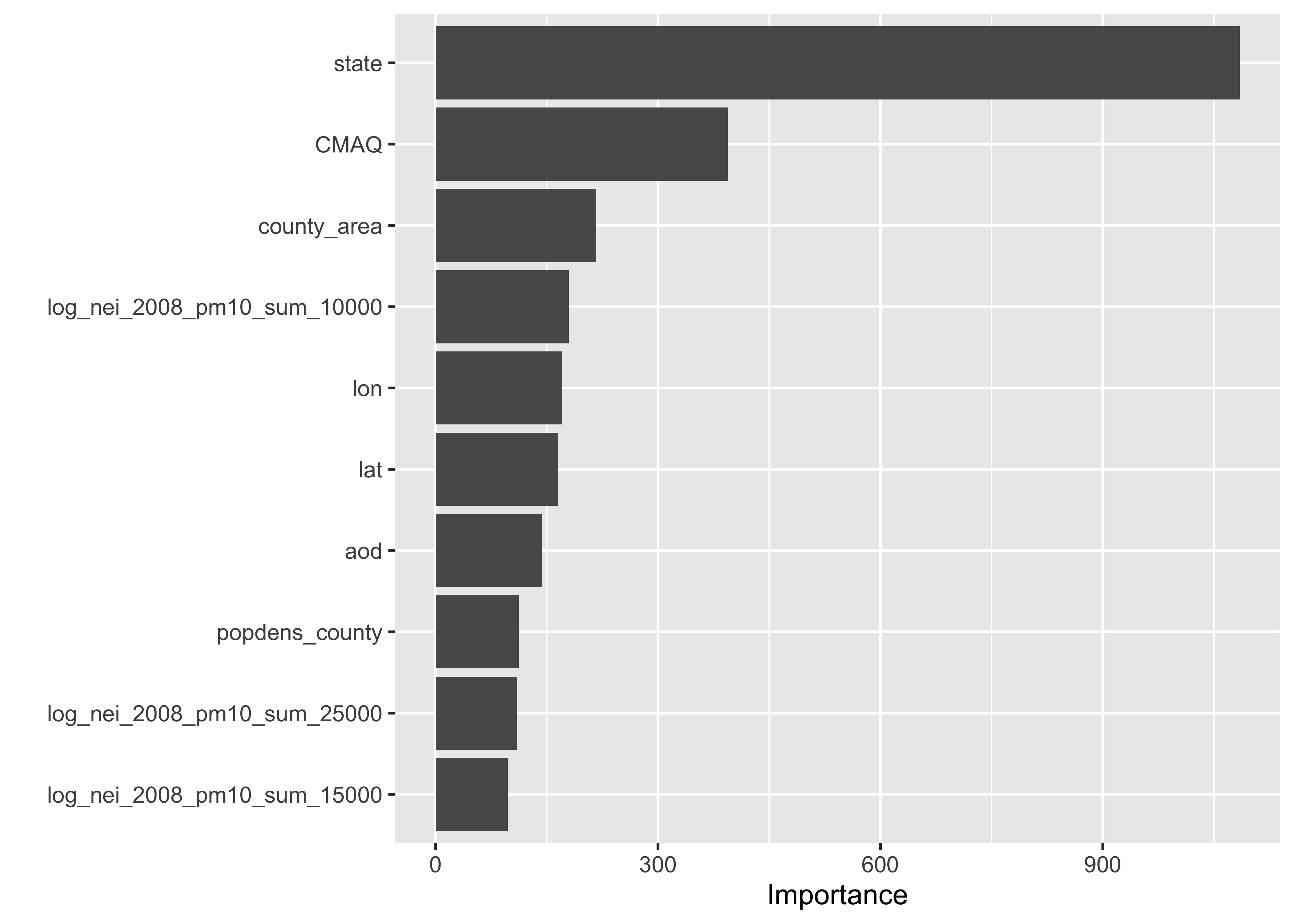
❓ What’s your interpretation of these results?
World map:
Just the US
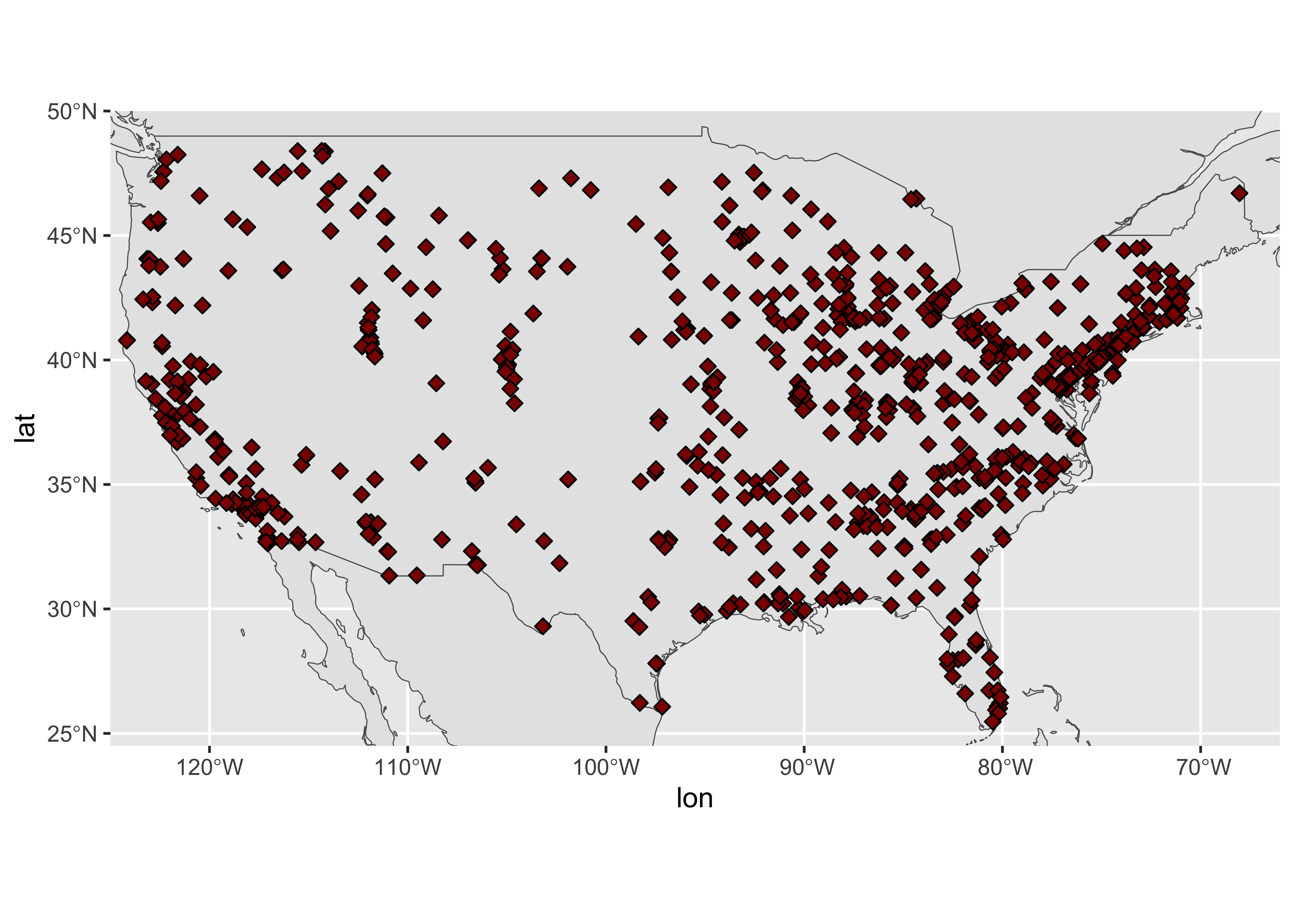
Monitor Data
Adding in our monitors…
The Map
monitors <- ggplot(data = world) +
geom_sf(data = counties, fill = NA, color = gray(.5))+
coord_sf(xlim = c(-125, -66), ylim = c(24.5, 50),
expand = FALSE) +
geom_point(data = pm, aes(x = lon, y = lat), size = 2,
shape = 23, fill = "darkred") +
ggtitle("Monitor Locations") +
theme(axis.title.x=element_blank(),
axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
axis.title.y = element_blank(),
axis.text.y = element_blank(),
axis.ticks.y = element_blank())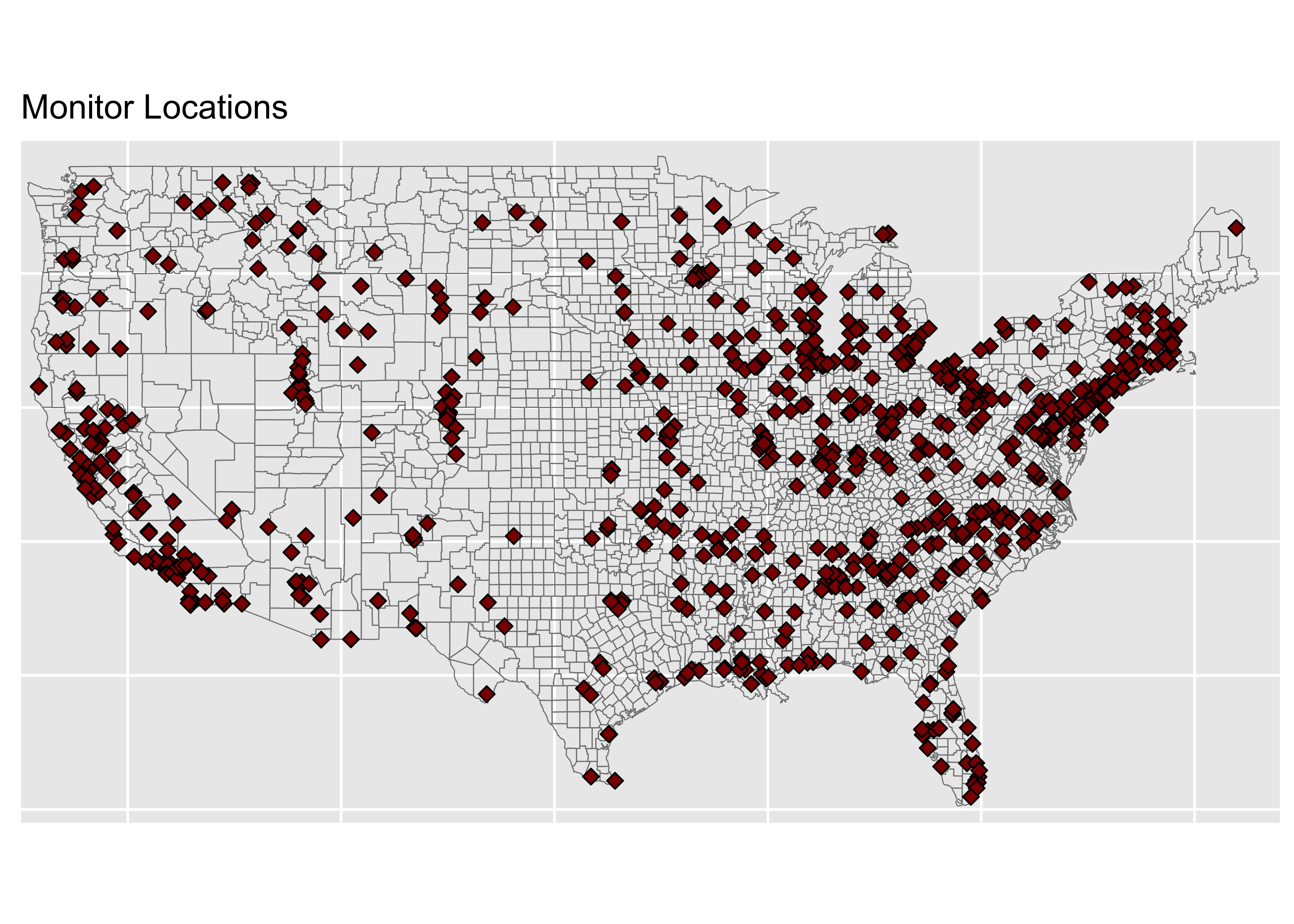
Map: Truth
truth <- ggplot(data = world) +
coord_sf(xlim = c(-125,-66),
ylim = c(24.5, 50),
expand = FALSE) +
geom_sf(data = map_data, aes(fill = value)) +
scale_fill_gradientn(colours = topo.colors(7),
na.value = "transparent",
breaks = c(0, 10, 20),
labels = c(0, 10, 20),
limits = c(0, 23.5),
name = "PM ug/m3") +
ggtitle("True PM 2.5 levels") +
theme(axis.title.x = element_blank(),
axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
axis.title.y = element_blank(),
axis.text.y = element_blank(),
axis.ticks.y = element_blank())Coordinate system already present. Adding new coordinate system, which will
replace the existing one.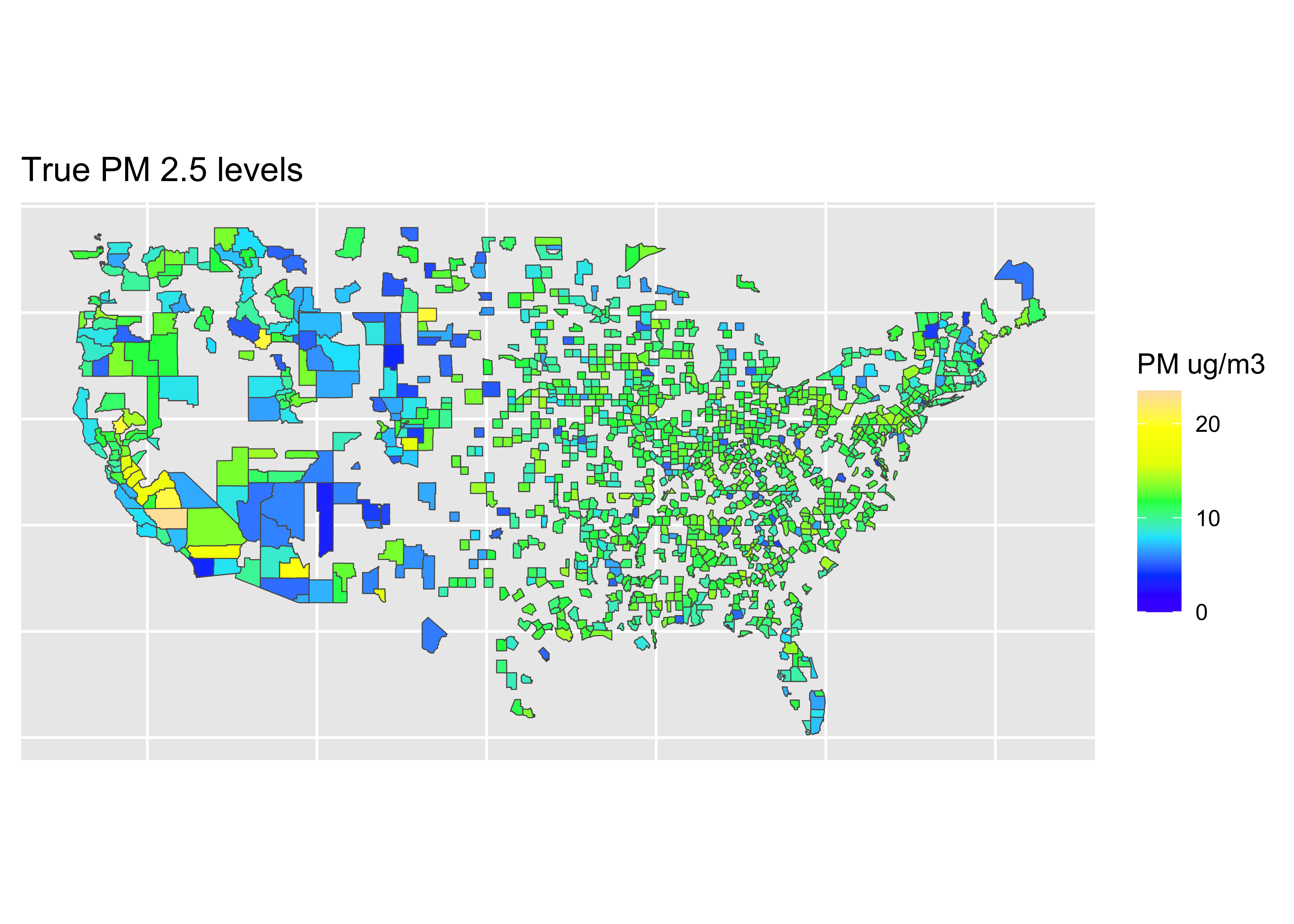
Map: Predictions
# fit data
RF_final_train_fit <- parsnip::fit(RF_tuned_wflow, data = train_pm)
RF_final_test_fit <- parsnip::fit(RF_tuned_wflow, data = test_pm)
# get predictions on training data
values_pred_train <- predict(RF_final_train_fit, train_pm) |>
bind_cols(train_pm |> select(value, fips, county, id))
# get predictions on testing data
values_pred_test <- predict(RF_final_test_fit, test_pm) |>
bind_cols(test_pm |> select(value, fips, county, id))
values_pred_test# A tibble: 292 × 5
.pred value fips county id
<dbl> <dbl> <fct> <chr> <fct>
1 11.6 11.2 1033 Colbert 1033.1002
2 11.9 12.4 1055 Etowah 1055.001
3 11.1 10.5 1069 Houston 1069.0003
4 13.9 15.6 1073 Jefferson 1073.0023
5 12.0 12.4 1073 Jefferson 1073.1005
6 11.3 11.1 1073 Jefferson 1073.1009
7 11.5 11.8 1073 Jefferson 1073.5003
8 11.0 10.0 1097 Mobile 1097.0003
9 11.9 12.0 1101 Montgomery 1101.0007
10 12.9 13.2 1113 Russell 1113.0001
# ℹ 282 more rowsmap_data <- inner_join(counties, all_pred, by = "county")
pred <- ggplot(data = world) +
coord_sf(xlim = c(-125,-66),
ylim = c(24.5, 50),
expand = FALSE) +
geom_sf(data = map_data, aes(fill = .pred)) +
scale_fill_gradientn(colours = topo.colors(7),
na.value = "transparent",
breaks = c(0, 10, 20),
labels = c(0, 10, 20),
limits = c(0, 23.5),
name = "PM ug/m3") +
ggtitle("Predicted PM 2.5 levels") +
theme(axis.title.x=element_blank(),
axis.text.x=element_blank(),
axis.ticks.x=element_blank(),
axis.title.y=element_blank(),
axis.text.y=element_blank(),
axis.ticks.y=element_blank())Coordinate system already present. Adding new coordinate system, which will
replace the existing one.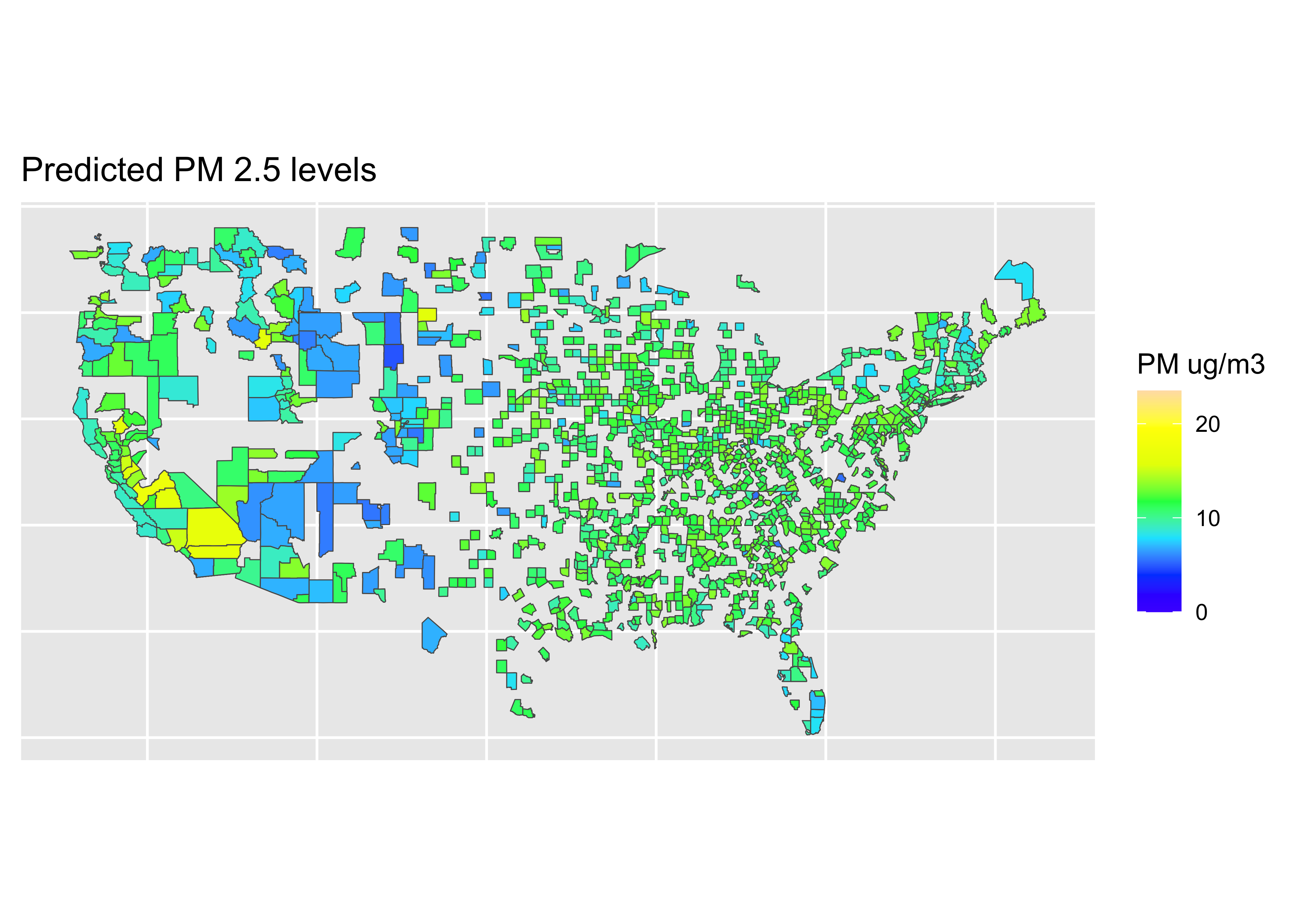
Final Plot
:::panel-tabset
Code
library(patchwork)
final_plot <- (truth/pred) +
plot_annotation(title = "Machine Learning Methods Allow for Prediction of Air Pollution", subtitle = "A random forest model predicts true monitored levels of fine particulate matter (PM 2.5) air pollution based on\ndata about population density and other predictors reasonably well, thus suggesting that we can use similar methods to predict levels\nof pollution in places with poor monitoring",
theme = theme(plot.title = element_text(size =12, face = "bold"),
plot.subtitle = element_text(size = 8)))Plot
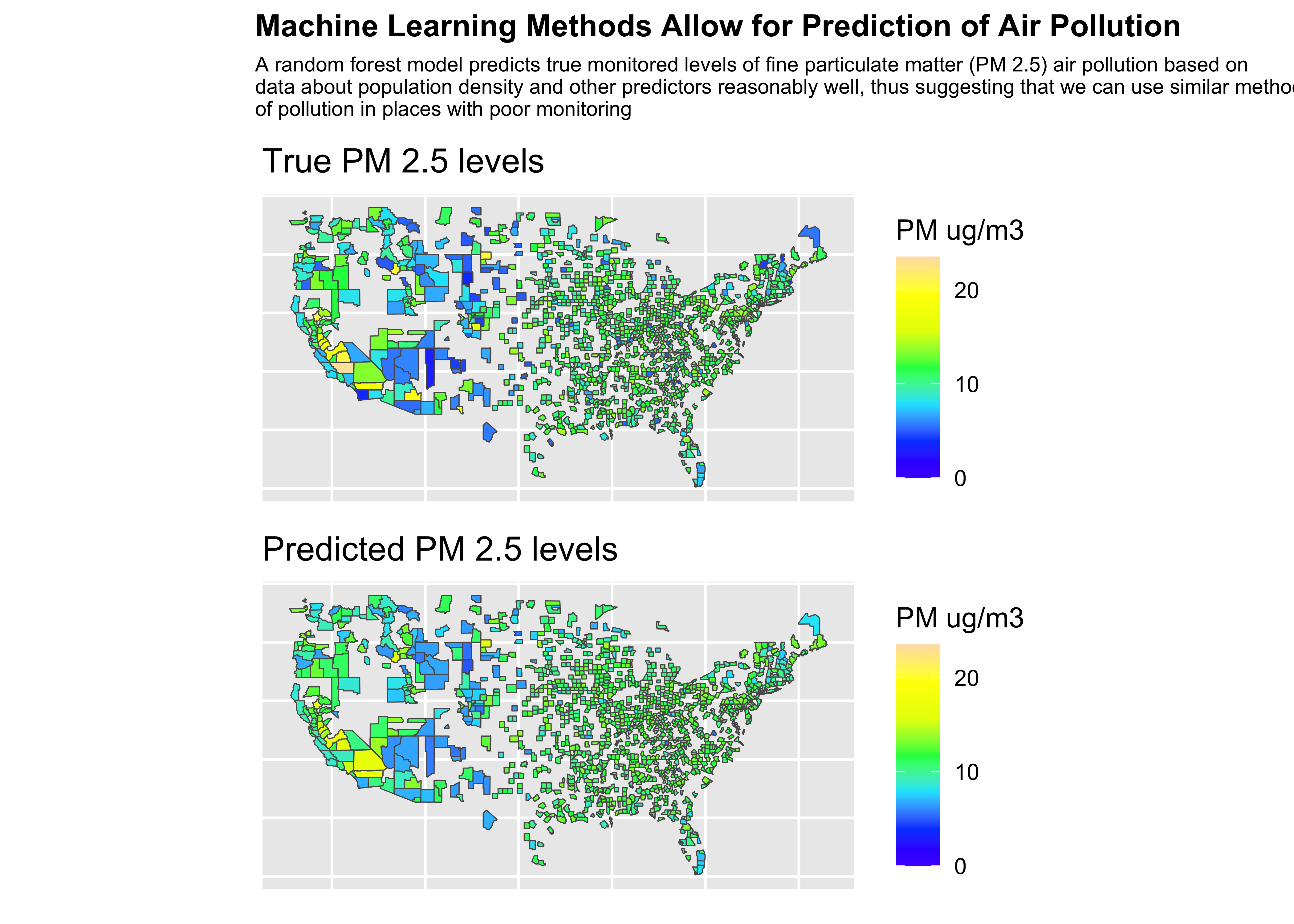
❓ What do you learn from these results?
Your Case Study
- Can you copy + paste code directly from here to answer the question? Yes.
- Do you have to present linear regression model and random forest? No
- Should you present anything from the 12-regression notes? Probably not. (This is why HW03 and lab07 focus on regression)
- Could you try an additional model as your extension? Yes!
- Does that model have to be “better”? No! But, consider the story!
- Could you try to identify the simplest, accurate model as an extension? Yes.
![]()